Hi all, this time I decided to share my knowledge about Linux clustering with you as a series of guides titled “Linux Clustering For a Failover Scenario“.

Following are the 4-article series about Clustering in Linux:
First of all, you will need to know what clustering is, how it is used in industry and what kind of advantages and drawbacks it has etc.
What is Clustering
Clustering is establishing connectivity among two or more servers in order to make it work like one. Clustering is a very popular technic among Sys-Engineers that they can cluster servers as a failover system, a load balance system or a parallel processing unit.
By this series of guide, I hope to guide you to create a Linux cluster with two nodes on RedHat/CentOS for a failover scenario.
Since now you have a basic idea of what clustering is, let’s find out what it means when it comes to failover clustering. A failover cluster is a set of servers that works together to maintain the high availability of applications and services.
For an example, if a server fails at some point, another node (server) will take over the load and gives end user no experience of down time. For this kind of scenario, we need at least 2 or 3 servers to make the proper configurations.
I prefer we use 3 servers; one server as the red hat cluster enabled server and others as nodes (back end servers). Let’s look at below diagram for better understanding.
Cluster Server: 172.16.1.250 Hostname: clserver.test.net node01: 172.16.1.222 Hostname: nd01server.test.net node02: 172.16.1.223 Hostname: nd02server.test.net
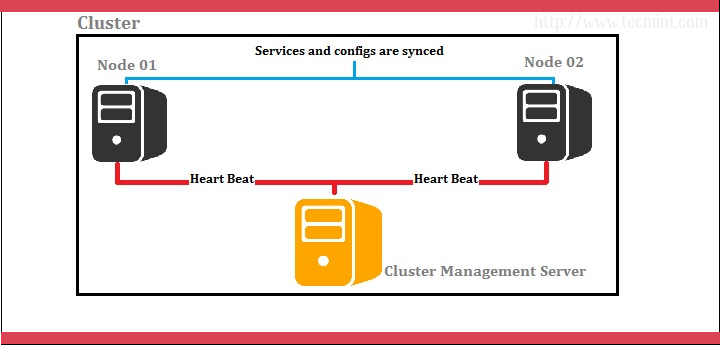
In above scenario, cluster management is done by a separate server and it handles two nodes as shown by the diagram. Cluster management server constantly sends heartbeat signals to both nodes to check whether if anyone is failing. If anyone has failed, the other node takes over the load.
Advantages of Clustering Servers
- Clustering servers is completely a scalable solution. You can add resources to the cluster afterwards.
- If a server in the cluster needs any maintenance, you can do it by stopping it while handing the load over to other servers.
- Among high availability options, clustering takes a special place since it is reliable and easy to configure. In case of a server is having a problem providing the services furthermore, other servers in the cluster can take the load.
Disadvantages of Clustering Servers
- Cost is high. Since the cluster needs good hardware and a design, it will be costly comparing to a non-clustered server management design. Being not cost effective is a main disadvantage of this particular design.
- Since clustering needs more servers and hardware to establish one, monitoring and maintenance is hard. Thus increase the infrastructure.
Now let’s see what kind of packages/installations we need to configure this setup successfully. The following packages/RPMs can be downloaded by rpmfind.net.
- Ricci (ricci-0.16.2-75.el6.x86_64.rpm)
- Luci (luci-0.26.0-63.el6.centos.x86_64.rpm)
- Mod_cluster (modcluster-0.16.2-29.el6.x86_64.rpm)
- CCS (ccs-0.16.2-75.el6_6.2.x86_64.rpm)
- CMAN(cman-3.0.12.1-68.el6.x86_64.rpm)
- Clusterlib (clusterlib-3.0.12.1-68.el6.x86_64.rpm)
Let’s see what each installation does for us and their meanings.
- Ricci is a daemon which used for cluster management and configurations. It distributes/dispatches receiving messages to the nodes configured.
- Luci is a server that runs on the cluster management server and communicates with other multiple nodes. It provides a web interface to make things easier.
- Mod_cluster is a load balancer utility based on httpd services and here it is used to communicate the incoming requests with the underlying nodes.
- CCS is used to create and modify the cluster configuration on remote nodes through ricci. It is also used to start and stop the cluster services.
- CMAN is one of the primary utilities other than ricci and luci for this particular setup, since this acts as the cluster manager. Actually, cman stands for CLUSTER MANAGER. It is a high-availability add-on for RedHat which is distributed among the nodes in the cluster.
Read the article, understand the scenario we’re going to create the solution to, and set the pre-requisites for the implementation. Let’s meet with the Part 2, in our upcoming article, where we learn How to install and create the cluster for the given scenario.
References:
Keep connected with Tecmint for handy and latest How To’s. Stay Tuned up for the part 02 (Linux Servers clustering with 2 Nodes for a failover scenario on RedHAT/CentOS – Creating the cluster) soon.




In your scenario, we have two nodes and one cluster management server, suppose our cluster management server goes down due to any XYZ reason then what we will do? In this case, it’s not a high availability system.
Does the cluster run as a background application?
If I wanted to play solitare on an individual machine would it run on the cluster or as an app on one of the host machines?
Hi Thilina,
Good Article. Is it possible to use one cluster manager box to mange two clusters?
I’ve never tried. But cannot be impossible. I’ll keep you posted if I come across such scenario.
Hi,
I have a doubt that can we create shared storage through ISCSI disk service. if yes can you tell me how to setup the ISCSI disk in the rhel server?
Thanks
Saravanan
We actually can do that but a little bit of different approach on that. Will try to provide an article on that.
Hi,
I have many issues with dependencies in RHEL 6 like mod_cluster any many other like ricci not found I have to do manually with rpm -ivh which causes many issues instead of on yum. It’s a very good article, but more explanation required like fencing and iscsi creation etc..
I will try doing a separate one regarding fencing and iscsi. Till then hope following will help you.
https://www.tecmint.com/what-is-quorum-disk-and-a-fencing-wars/
We have an SGI cluster .SUSE 11 installed on it. from few days on master node only cd and echo commands are working. data is their on cluster.
so it is OS crash problem or something else.
I believe either the node is in read-only mode. Or some commands are removed from the server. The information you provided is not sufficient for a detailed answer.
how we can remove read only mode?????
Depending on the error messages, you could decide it is still safe to use file-system and return it read-write condition with mount -o remount,rw
It’s a bit hard to give resolutions to issue without looking at them.
I believe the servers are started up in read-only mood. Can you or your sys Admins check that? Better to back up your data and resolve the issue in the cluster soon to avoid a data loss.
It seems an issue in the OS. Looks like the server is running on read-only mode.
Thanks a lot for sharing your knowledge to us. I have learnt real experience about cluster. Have one more query, is it possible to implement cluster in all RHEL versions. (RHEL5/6/7)?
Thanx Ramesh. Yes you can do it in RHEL. But the articles I provided are more relevant to RHEL 6 because RHEL has depricated some packages in RHEL 7 and also RHEL 5 is outdated now
Hi
I have two question 1)for connecting two nodes together and them to server, do you use hub? or lan?
2) this method test on which version linux x86_64? centos 7? or ?
thanks
Hi Hamid,
I used LAN and RHEL 6.x
Hello, Thanks for the tutorial. Am wondering if these packages are available for debian-based distros such as Ubuntu too?
David,
cman you can use. But i dont think ricci, luci and other packs are available. You may use corosync, pacemaker, pcs etc. on ubuntu
Hi Thilina, what´s about haproxy?
Adrian,
HA proxy is also a reputed tool for the same purpose. And is used by many industrial giants. You can expect an article for HA in near future.
Hi Ravi, I couldn’t find the clustering rpm packages(ricci, luci, ccs, CMAN, cluster lib) to download, can you please give me the exact path for it, so that i would be helpfull
Hi Murali,
You can try following URL.
http://vault.centos.org/6.4/os/x86_64/Packages/
Wow! This is really good material, nicely and explained using simple language. As a newbie, I have found it helpful, thanks for sharing such helpful information, really inspiring, a big up to you.
Thank you.
Thank you Givious ! ! ! !
When you are going to publish Part 4: Syncing the Configurations and Starting Up the Clustering
I have completed all 3 parts
Hi Vinay,
Great. I will post the last part soon. Sorry for the delay
Hi, first, I want to congratulate you for your website and excellent tutorials!! Great job and thanks for sharing your knowledge.. My doubt is about the Cluster Management Server, what if it fails? Is there a solution within the clustering system, or it is necessary to implement a contingency plan?
Thanks in advantage!
Hi Heriberto,
Thank you for your interest for the post. For the question you ask, It is necessary to implement a contingency plan if you have critical and important data in the cluster. You can setup a fail-over for the cluster management server and services. But this way, it will cause additional costs for the resources. I will share with you if I could find a different and more convenient solution regarding this.
Hi Dipanjan,
For two different geographical DC location, you may prefer GRID computing.
I am eagerly waiting for your next article. Please make it hurry if you can. Thanks.
Hi Mohammad,
Thanx for your interest. Will post it ASAP.
Hi Mohommad,
Part 2 and part 3 are already posted. Will post part 4 soon.
There is another big disadvantage in rhel cluster that we are facing everyday in our environment. That is red hat officially does not support extended distance (xd or stage) cluster,that located on two different geographical DC location. Even no solution for this.
Hi Dipanjan,
Thanx for sharing your knowledge :)