High Availability (HA) simply refers to a quality of a system to operate continuously without failure for a long period of time. HA solutions can be implemented using hardware and/or software, and one of the common solutions to implementing HA is clustering.
In computing, a cluster is made up of two or more computers (commonly known as nodes or members) that work together to perform a task. In such a setup, only one node provides the service with the secondary node(s) taking over if it fails.
Clusters fall into four major types:
- Storage: provide a consistent file system image across servers in a cluster, allowing the servers to simultaneously read and write to a single shared file system.
- High Availability: eliminate single points of failure and by failing over services from one cluster node to another in case a node goes becomes inoperative.
- Load Balancing: dispatch network service requests to multiple cluster nodes to balance the request load among the cluster nodes.
- High Performance: carry out parallel or concurrent processing, thus helping to improve performance of applications.
Another widely used solution to providing HA is replication (specifically data replications). Replication is the process by which one or more (secondary) databases can be kept in sync with a single primary (or master) database.
To setup a cluster, we need at least two servers. For the purpose of this guide, we will use two Linux servers:
- Node1: 192.168.10.10
- Node2: 192.168.10.11
In this article, we will demonstrate the basics of how to deploy, configure and maintain high availability/clustering in Ubuntu 16.04/18.04 and CentOS 7. We will demonstrate how to add Nginx HTTP service to the cluster.
Configuring Local DNS Settings on Each Server
In order for the two servers to communicate to each other, we need to configure the appropriate local DNS settings in the /etc/hosts file on both servers.
Open and edit the file using your favorite command line editor.
$ sudo vim /etc/hosts
Add the following entries with actual IP addresses of your servers.
192.168.10.10 node1.example.com 192.168.10.11 node2.example.com
Save the changes and close the file.
Installing Nginx Web Server
Now install Nginx web server using the following commands.
$ sudo apt install nginx [On Ubuntu] $ sudo yum install epel-release && sudo yum install nginx [On CentOS 7]
Once the installation is complete, start the Nginx service for now and enable it to auto-start at boot time, then check if it’s up and running using the systemctl command.
On Ubuntu, the service should be started automatically immediately after package pre-configuration is complete, you can simply enable it.
$ sudo systemctl enable nginx $ sudo systemctl start nginx $ sudo systemctl status nginx
After starting the Nginx service, we need to create custom webpages for identifying and testing operations on both servers. We will modify the contents of the default Nginx index page as shown.
$ echo "This is the default page for node1.example.com" | sudo tee /usr/share/nginx/html/index.html #VPS1 $ echo "This is the default page for node2.example.com" | sudo tee /usr/share/nginx/html/index.html #VPS2
Installing and Configuring Corosync and Pacemaker
Next, we have to install Pacemaker, Corosync, and Pcs on each node as follows.
$ sudo apt install corosync pacemaker pcs #Ubuntu $ sudo yum install corosync pacemaker pcs #CentOS
Once the installation is complete, make sure that pcs daemon is running on both servers.
$ sudo systemctl enable pcsd $ sudo systemctl start pcsd $ sudo systemctl status pcsd
Creating the Cluster
During the installation, a system user called “hacluster” is created. So we need to set up the authentication needed for pcs. Let’s start by creating a new password for the “hacluster” user, we need to use the same password on all servers:
$ sudo passwd hacluster

Next, on one of the servers (Node1), run the following command to set up the authentication needed for pcs.
$ sudo pcs cluster auth node1.example.com node2.example.com -u hacluster -p password_here --force

Now create a cluster and populate it with some nodes (the cluster name cannot exceed 15 characters, in this example, we have used examplecluster) on Node1 server.
$ sudo pcs cluster setup --name examplecluster node1.example.com node2.example.com
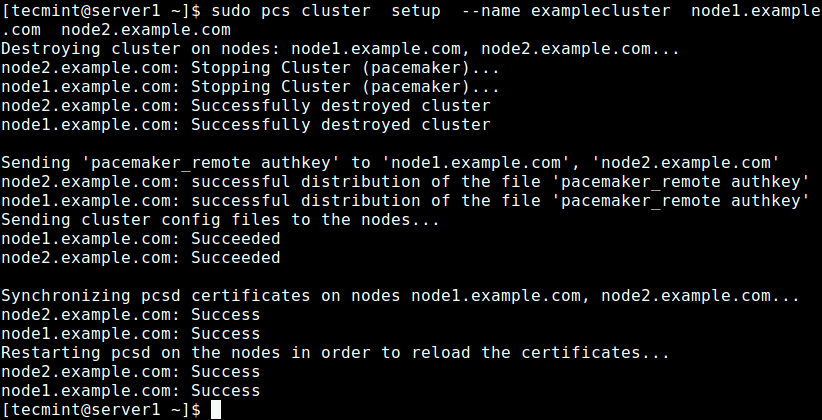
Now enable the cluster on boot and start the service.
$ sudo pcs cluster enable --all $ sudo pcs cluster start --all
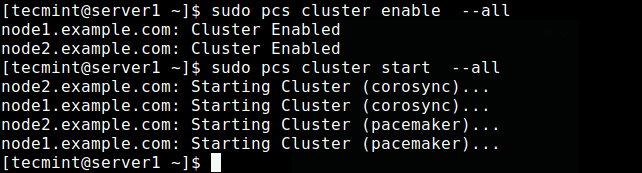
Now check if the cluster service is up and running using the following command.
$ sudo pcs status OR $ sudo crm_mon -1
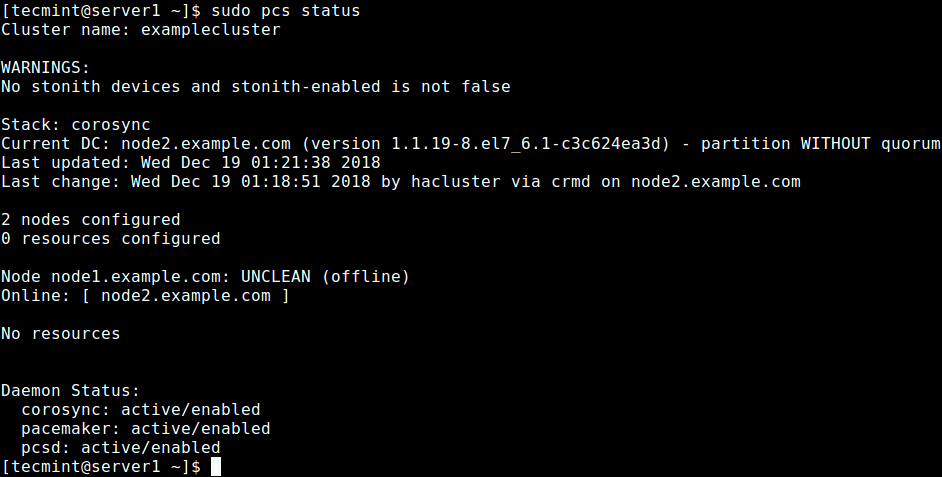
From the output of the above command, you can see that there is a warning about no STONITH devices yet the STONITH is still enabled in the cluster. In addition, no cluster resources/services have been configured.
Configuring Cluster Options
The first option is to disable STONITH (or Shoot The Other Node In The Head), the fencing implementation on Pacemaker.
This component helps to protect your data from being corrupted by concurrent access. For the purpose of this guide, we will disable it since we have not configured any devices.
To turn off STONITH, run the following command:
$ sudo pcs property set stonith-enabled=false
Next, also ignore the Quorum policy by running the following command:
$ sudo pcs property set no-quorum-policy=ignore
After setting the above options, run the following command to see the property list and ensure that the above options, stonith and the quorum policy are disabled.
$ sudo pcs property list
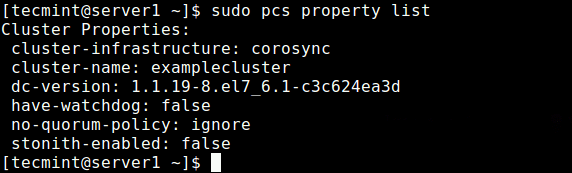
Adding a Resource/Cluster Service
In this section, we will look at how to add a cluster resource. We will configure a floating IP which is the IP address that can be instantly moved from one server to another within the same network or data center. In short, a floating IP is a technical common term, used for IPs which are not bound strictly to one single interface.
In this case, it will be used to support failover in a high-availability cluster. Keep in mind that floating IPs aren’t just for failover situations, they have a few other use cases. We need to configure the cluster in such a way that only the active member of the cluster “owns” or responds to the floating IP at any given time.
We will add two cluster resources: the floating IP address resource called “floating_ip” and a resource for the Nginx web server called “http_server”.
First start by adding the floating_ip as follows. In this example, our floating IP address is 192.168.10.20.
$ sudo pcs resource create floating_ip ocf:heartbeat:IPaddr2 ip=192.168.10.20 cidr_netmask=24 op monitor interval=60s
where:
- floating_ip: is the name of the service.
- “ocf:heartbeat:IPaddr2”: tells Pacemaker which script to use, IPaddr2 in this case, which namespace it is in (pacemaker) and what standard it conforms to ocf.
- “op monitor interval=60s”: instructs Pacemaker to check the health of this service every one minutes by calling the agent’s monitor action.
Then add the second resource, named http_server. Here, resource agent of the service is ocf:heartbeat:nginx.
$ sudo pcs resource create http_server ocf:heartbeat:nginx configfile="/etc/nginx/nginx.conf" op monitor timeout="20s" interval="60s"
Once you have added the cluster services, issue the following command to check the status of resources.
$ sudo pcs status resources

Looking at the output of the command, the two added resources: “floating_ip” and “http_server” have been listed. The floating_ip service is off because the primary node is in operation.
If you have firewall enabled on your system, you need to allow all traffic to Nginx and all high availability services through the firewall for proper communication between nodes:
-------------- CentOS 7 -------------- $ sudo firewall-cmd --permanent --add-service=http $ sudo firewall-cmd --permanent --add-service=high-availability $ sudo firewall-cmd --reload -------------- Ubuntu -------------- $ sudo ufw allow http $ sudo ufw allow high-availability $ sudo ufw reload
Testing High Availability/Clustering
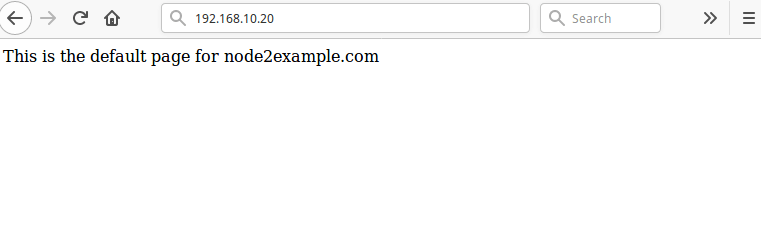
The final and important step is to test that our high availability setup works. Open a web browser and navigate to the address 192.168.10.20 you should see the default Nginx page from the node2.example.com as shown in the screenshot.
To simulate a failure, run the following command to stop the cluster on the node2.example.com.
$ sudo pcs cluster stop http_server
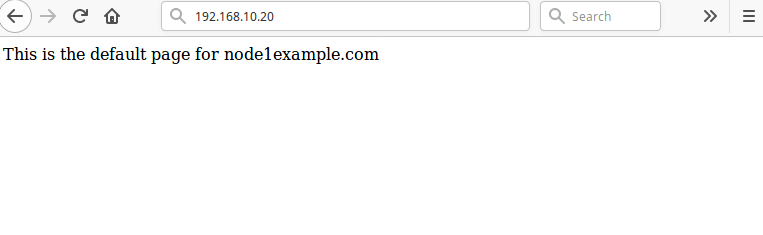
Then reload the page at 192.168.10.20, you should now access the default Nginx web page from the node1.example.com.
Alternatively, you can simulate an error by telling the service to stop directly, without stopping the the cluster on any node, using the following command on one of the nodes:
$ sudo crm_resource --resource http_server --force-stop
Then you need to run crm_mon in interactive mode (the default), within the monitor interval of 2 minutes, you should be able to see the cluster notice that http_server failed and move it to another node.
For your cluster services to run efficiently, you may need to set some constraints. You can see the pcs man page (man pcs) for a list of all usage commands.
For more information on Corosync and Pacemaker, check out: https://clusterlabs.org/
Summary
In this guide, we have shown the basics of how to deploy, configure and maintain high availability/clustering/replication in Ubuntu 16.04/18.04 and CentOS 7. We demonstrated how to add Nginx HTTP service to a cluster. If you have any thoughts to share or questions, use the feedback form below.





Hi Aaron,
I am getting this output..
$ sudo pcs status resources
$ sudo pcs cluster stop http_server
floating_ip (ocf::heartbeat:IPaddr2): Started hacluster1
http_server (ocf::heartbeat:nginx): Started hacluster2
Error: nodes 'http_server' do not appear to exist in configuration
In that case, how do I test, I am not able to switch between these.
Please help.
Regards,
zain
root@Application-node-01:~# sudo pcs cluster setup –name ha_lecluster mofapp1.local.la
Error: Specified option ‘–name’ is not supported in this command
Hint: Syntax has changed from the previous version. See ‘man pcs’ -> Changes in pcs-0.10.
Please help
I used Ubuntu 20.04.
Try sudo pcs cluster setup ha_lecluster mofapp1.local.la
Hi, Thanks for the article,
Is this HA is suitable for ntp service? if yes can you provide the detailed commands to add the ntp service?
Thanks, And Regards,
Sravan
Hi,
Kindly please help me understand, Why we have taken floating IP as 192.169.10.20? as our node1 and node2 have (Node1: 192.168.10.10 / Node2: 192.168.10.1).
Thanks in advance.
Suyash
I’m not 100% about my answer, but we have 10.10 and 10.1 as nginx client, and for the front end the address will be 10.20, it means that our servers can have any ip address, the browser will always receive the requests as 192.168.10.20 and nginx will forward the requests to Node1: 192.168.10.10 or Node2: 192.168.10.1 depending on the availability.
Hello, I did the test and gave me the following command error in Ubuntu 20.
The command is this:
Error: Specified options ‘–force’ is not supported on this command .. What do I do?
@Ulundo
Try to use
--forceinstead of -force.Doesn’t work for work…
Hi,
Please clarify the below,
Thanks in Advance!
@Suresh
This does not require NGINX Plus and maybe you need to read more about IP addressing and subnetting and how to do it in a production environment.
Hello,
As I know the STONITH should not be disabled in production. I don’t think this article is recommended to use in production.
Hello. I wrote down because I had a question.
I want to check the failover time of the pacemaker. The failover time that I mean is the time when node1 is down and node2 is up.
I wonder if there are any data provided by the pacemaker about the failover time. If not, how can I check the failover time?
I wrote the source code with Python, and I wrote the
sudo pcs cluster stop node1into the console window, and then I took the time.In node2, the node1 was monitored through the
sudo pcs statusandsudo crm_mon -1, and measured the time if the node1 went offline.But when I measured the time, I was wondering if I could measure it this way because it’s longer than I thought.
I’m curious about your answer. Please reply.
[solved] first, In my case the same symptom occurred: floating_ip consistently runs on serverA while http_server runs on serverB.
It was a very difficult situation and the secret was in grouping…
That’s It! running fine without any issues..
@Pippin
Thanks a lot for sharing this solution. It’s a great addition to this guide.
You should move the firewall exceptions bit up higher in the config as ports needs to be opened to properly jump start the cluster. Also, I ran through this twice and the command “
sudo pcs cluster stop http_server” tells me “nodes ‘http_server‘ do not appear to exist in configuration.In addition to the above issues, floating_ip consistently runs on serverA while http_server runs on serverB. So the site is offline at the floating IP and at the IP of the server that has the floating ip.
sudo ufw allowhigh-availabilitythis is not working, there is no such command for ufw.
I’ve problem with starting the corosync & pacemaker services.
Please check the snapshot below.
https://imgur.com/a/Xhaf5pn
Thank you for this tutorial. I have a setup with a gateway configured with 2 interfaces eth0 with 10 public IP addresses, and eth1 with a local IP (10.0.0.1) address. I am then using iptables for nat, and nginx working as a reverse proxy.
Behind this, I have multiple servers running different services all with the network 10.0.0.x and using the 10.0.0.1 as a gateway. I need to add a secondary gateway as a failover, as the datacenter its a 4h drive. If one of the gateways dies, the other one will move the 10 public IP addresses and one local to the other gateway.
Can this be done using this configuration? Can I have the multi public IPs and a local one floating from one server to the other? Any help will be appreciated.
Can I use public IP for the cluster IP address while server IP maintain private?
@ariuan
Yes you can.
I see it is not a balanced approach.
Is it possible to create balanced with round-robin rule for example?
@Ievgen
Sure, this is a basic setup for beginners to get started with HA, we will work on advanced setups in the future, and possibly cover the approach you are recommending. Thanks for the feedback.
Hi,
I have followed all step, but I can’t connect with my second node.
Error: Unable to communicate with node2.example.com
How can I resolve?
Anyone please suggest me.
Flush all the IP tables on both the servers with the command “
iptables -F“.Any idea how to get this running on virtualbox? I did all the steps, but can’t access the nginx server.
@John
You need to configure host-only networking between the virtual machines and the host for it to work. For more information, see: https://www.tecmint.com/network-between-guest-vm-and-host-virtualbox/
Also, you don’t want services controller by Pacemaker to start at boot. Pacemaker is the only thing that should be starting/stopping services.
Without collocation constraints your VIP and WWW server will end up on different nodes. Also, where’s the replicated storage? DRBD is open source, ships with Ubuntu, and is easy to setup so maybe that’s an easy add.
One more thing about STONITH: stop operation failures will leave you dead in the water without it, but the setup is very particular to your environment, so I would leave that as an exercise for the reader too. Add proper constraints and something for replication and this is a good primer!
@Matt
We will do a little research on collocation constraints and update the guide to include them. We are working on a separate guide for DRBD, which we will link to this guide. Thanks a ton for sharing this useful feedback.
The main problem is that this approach does not take into account the state of application programs. If you are using an oracle database service, oracle does back itself up automatically. also even nfs files do not back themselves up.
A far better test of high availability is to just turn off one cluster and see what happens. If the ip address changes, and the mount occurs from one system to the other good. Now you have to have a way of journeling everything run on a server. that way when if fails you can run the journal on the disk to get it all back.
@steve
Many thanks for the useful additions, as we mentioned at the start of the guide, this is a basic setup to get started with high availability and clustering in Linux. One can always read the full documentation of the mentioned applications, to setup a better production-level HA/clustering environment.