Organizing your home directory or even system can be particularly hard if you have the habit of downloading all kinds of stuff from the internet using your download managers.
Often you may find you have downloaded the same mp3, pdf, and epub (and all kinds of other file extensions) and copied it to different directories. This may cause your directories to become cluttered with all kinds of useless duplicated stuff.
In this tutorial, you are going to learn how to find and delete duplicate files in Linux using rdfind, fdupes, and rmlint command-line tools, as well as using GUI tools called DupeGuru and FSlint.
A note of caution – always be careful what you delete on your system as this may lead to unwanted data loss. If you are using a new tool, first try it in a test directory where deleting files will not be a problem.
1. Rdfind – Find Duplicate Files in Linux
Rdfind comes from redundant data find, which is a free command-line tool used to find duplicate files across or within multiple directories. It recursively scans directories and identifies files that have identical content, allowing you to take appropriate actions such as deleting or moving the duplicates.
Rdfind uses an algorithm to classify the files and detects which of the duplicates is the original file and considers the rest as duplicates.
The rules of ranking are:
- If A was found while scanning an input argument earlier than B, A is higher ranked.
- If A was found at a depth lower than B, A is higher ranked.
- If A was found earlier than B, A is higher ranked.
The last rule is used particularly when two files are found in the same directory.
Install Rdfind on Linux
To install rdfind in Linux, use the following command as per your Linux distribution.
$ sudo apt install rdfind [On Debian, Ubuntu and Mint] $ sudo yum install rdfind [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/rdfind [On Gentoo Linux] $ sudo apk add rdfind [On Alpine Linux] $ sudo pacman -S rdfind [On Arch Linux] $ sudo zypper install rdfind [On OpenSUSE]
To run rdfind on a directory simply type rdfind and the target directory.
$ rdfind /home/user
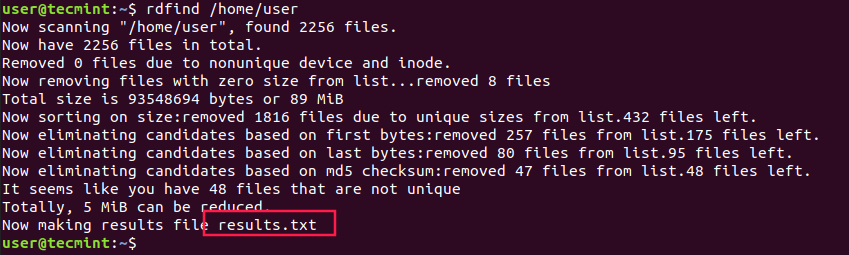
As you can see rdfind will save the results in a file called results.txt located in the same directory from where you ran the program. The file contains all the duplicate files that rdfind has found. You can review the file and remove the duplicate files manually if you want to.
Another thing you can do is to use the -dryrun an option that will provide a list of duplicates without taking any actions:
$ rdfind -dryrun true /home/user
When you find the duplicates, you can choose to replace them with hard links.
$ rdfind -makehardlinks true /home/user
And if you wish to delete the duplicates you can run.
$ rdfind -deleteduplicates true /home/user
To check other useful options of rdfind you can use the rdfind manual.
$ man rdfind
2. Fdupes – Scan for Duplicate Files in Linux
Fdupes is another command-line program that allows you to identify duplicate files on your system. It searches directories recursively, comparing file sizes and content to identify duplicates.
It uses the following methods to determine duplicate files:
- Comparing partial md5sum signatures
- Comparing full md5sum signatures
- byte-by-byte comparison verification
Just like rdfind, it has similar options:
- Search recursively
- Exclude empty files
- Shows the size of duplicate files
- Delete duplicates immediately
- Exclude files with a different owner
Install Fdupes in Linux
To install fdupes in Linux, use the following command as per your Linux distribution.
$ sudo apt install fdupes [On Debian, Ubuntu and Mint] $ sudo yum install fdupes [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/fdupes [On Gentoo Linux] $ sudo apk add fdupes [On Alpine Linux] $ sudo pacman -S fdupes [On Arch Linux] $ sudo zypper install fdupes [On OpenSUSE]
Fdupes syntax is similar to rdfind. Simply type the command followed by the directory you wish to scan.
$ fdupes <dir>
To search files recursively, you will have to specify the -r an option like this.
$ fdupes -r <dir>
You can also specify multiple directories and specify a dir to be searched recursively.
$ fdupes <dir1> -r <dir2>
To have fdupes calculate the size of the duplicate files use the -S option.
$ fdupes -S <dir>
To gather summarized information about the found files use the -m option.
$ fdupes -m <dir>

Finally, if you want to delete all duplicates use the -d an option like this.
$ fdupes -d <dir>
Fdupes will ask which of the found files to delete. You will need to enter the file number:
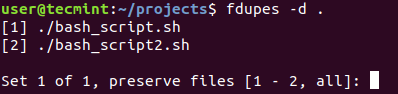
A solution that is definitely not recommended is to use the -N option which will result in preserving the first file only.
$ fdupes -dN <dir>
To get a list of available options to use with fdupes review the help page by running.
$ fdupes -help
3. Jdupes – Improved Fork of Fdupes
jdupes is a more modern fork of the classic fdupes, but it is much faster, actively maintained, and adds many features that fdupes doesn’t have.
Like fdupes, it finds duplicate files by comparing file contents, but it’s optimized for large datasets and heavy use cases.
Key improvements over fdupes:
- Much faster scanning on large directories (thanks to better algorithms and parallelization).
- Can replace duplicates with hard links to save space.
- Option to create symbolic links instead of deleting.
- More detailed output and advanced scripting options.
- Safer deletion options with interactive prompts.
Install Jdupes on Linux
To install Jdupes in Linux, use the following command as per your Linux distribution.
sudo apt install jdupes # Debian, Ubuntu, Mint sudo yum install jdupes # RHEL, CentOS, Fedora, Rocky, AlmaLinux sudo pacman -S jdupes # Arch Linux sudo zypper install jdupes # openSUSE
Usage examples:
jdupes <dir> # scan a directory jdupes -r <dir> # recursive scan jdupes -d <dir> # delete duplicates interactively jdupes -L <dir> # replace duplicates with hardlinks jdupes -s <dir> # replace with symlinks
Check more options with:
jdupes --help
4. Rmlint – Remove Duplicate Files
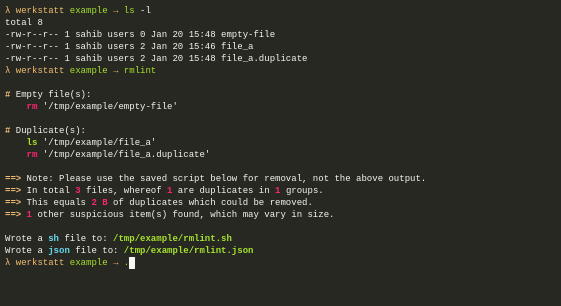
Rmlint is a command-line tool that is used for finding and removing duplicate and lint-like files in Linux systems. It helps identify files with identical content, as well as various forms of redundancy or lint, such as empty files, broken symbolic links, and orphaned files.
Install Rmlint on Linux
To install Rmlint in Linux, use the following command as per your Linux distribution.
$ sudo apt install rmlint [On Debian, Ubuntu and Mint] $ sudo yum install rmlint [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/rmlint [On Gentoo Linux] $ sudo apk add rmlint [On Alpine Linux] $ sudo pacman -S rmlint [On Arch Linux] $ sudo zypper install rmlint [On OpenSUSE]
5. dupeGuru – Find Duplicate Files in a Linux
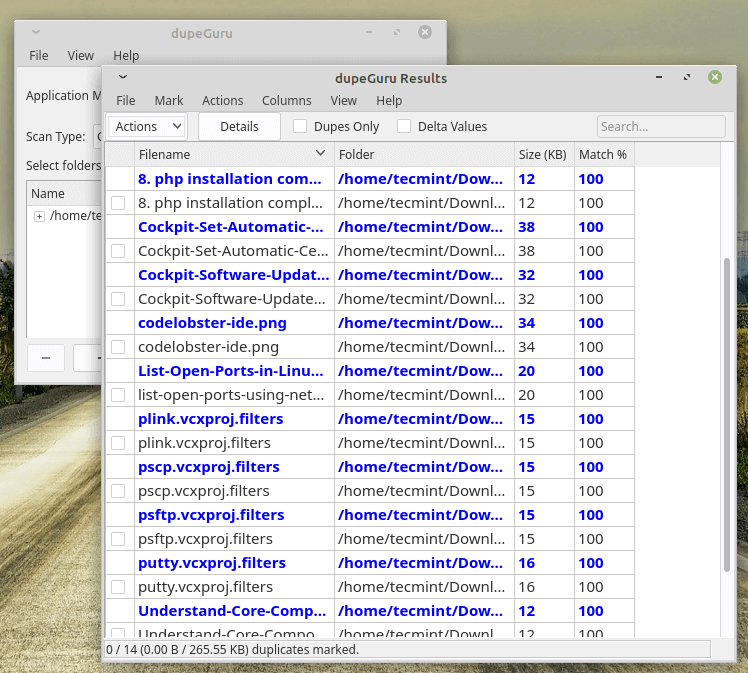
dupeGuru is an open-source and cross-platform tool that can be used to find duplicate files in a Linux system. The tool can either scan filenames or content in one or more folders. It also allows you to find the filename that is similar to the files you are searching for.
dupeGuru comes in different versions for Windows, Mac, and Linux platforms. Its quick fuzzy matching algorithm feature helps you to find duplicate files within a minute. It is customizable, you can pull the exact duplicate files you want to, and Wipeout unwanted files from the system.
Install dupeGuru on Linux
To install dupeGuru in Linux, use the following command as per your Linux distribution.
$ sudo apt install dupeguru [On Debian, Ubuntu and Mint] $ sudo yum install dupeguru [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/dupeguru [On Gentoo Linux] $ sudo apk add dupeguru [On Alpine Linux] $ sudo pacman -S dupeguru [On Arch Linux] $ sudo zypper install dupeguru [On OpenSUSE]
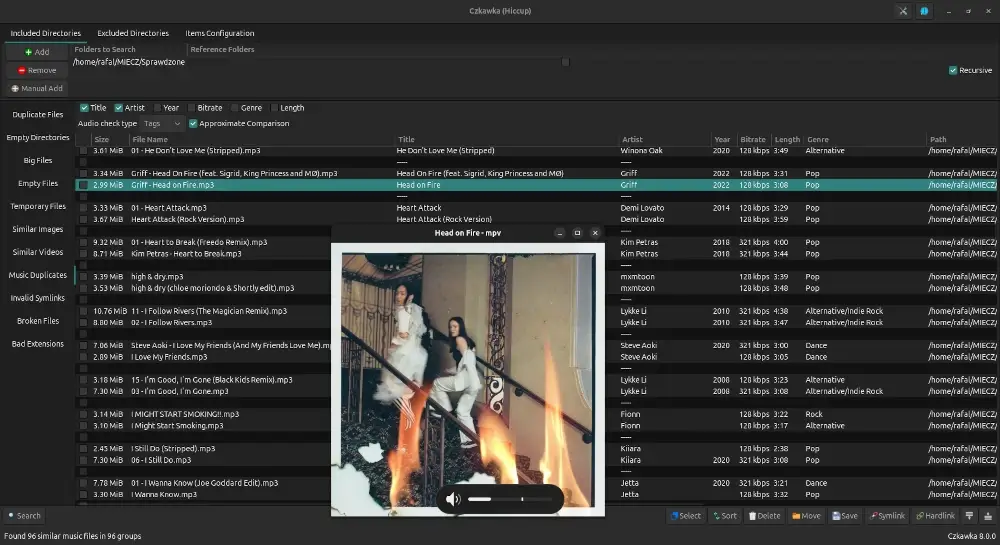
6. Czkawka – Modern Duplicate & File Cleanup Tool for Linux
Czkawka (pronounced “ch-kav-ka” – means “hiccup” in Polish) is a free, open-source utility built in Rust, that helps you find and remove unnecessary files from your system. It’s designed to be a fast, safe, and lightweight alternative to older tools like FSlint.
With Czkawka, you can detect duplicate files, empty folders, temporary files, broken symbolic links, and even large unused files. It provides both a command-line interface and a graphical interface for ease of use.
[WARNING] – snap version of this app is no longer maintained, you can use other package formats like flatpak or prebuilt binaries from official github project.
Czkawka isn’t included in most Linux repositories, but you can install it easily using Flatpak or Snap:
# Install via Flatpak (recommended) flatpak install flathub com.github.qarmin.czkawka # Install via Snap sudo snap install czkawka
Once installed, you can launch it from your application menu (for the GUI) or run it from the terminal using czkawka_cli.
czkawka_cli
Conclusion
These are very useful tools to find duplicated files on your Linux system, but you should be very careful when deleting such files.
If you are unsure if you need a file or not, it would be better to create a backup of that file and remember its directory prior to deleting it. If you have any questions or comments, please submit them in the comment section below.




I appreciate the article and I’m going to try rdfind with hardlinks. I know this article is a bit older, but I’d like to point out a wording correction:
For
fdupes -r, you wrote:‘To search files recursively, you will have to specify the
-roption like this.’Instead of ‘files,’ it should say ‘subdirectories’.
There’s an alternative (up-to-date) to fslint it’s called Czkawka and can be found in the Software Manager in Linux Minx (21.2).
It’s quite similar to fslint but more updated.
@Drs,
Thanks for the heads-up! I appreciate the recommendation. I’ll definitely check out Czkawka in the Software Manager.
Keeping things up-to-date is always a plus..
fslint is an excellent GUI tool for finding duplicate files in Linux systems, it also removes unnecessary or redundant files from the system.
As per my knowledge, the last significant update to FSlint was in 2015, and there have been no new releases or updates since then.
fdupes command-line tool is very useful in finding duplicate files in Linux systems by comparing file sizes and checksums to determine file duplication…
There is a new tool called dedup – ‘Identical File Finder and Deduplication’ – Searches for identical files on large directory trees.
For more info, visit – https://gitlab.com/lasthere/dedup
rdfind -makehardlinks true /home/ivor
Now scanning “/home/ivor”Dirlist.cc::handlepossiblefile: This should never happen. FIXME! details on the next row:
possiblefile=”/home/ivor/zfs”
, found 3007005 files.
Now have 3007005 files in total.
Removed 3609 files due to nonunique device and inode.
Total size is 2828024427719 bytes or 3 TiB
Removed 130576 files due to unique sizes from list.2872820 files left.
Now eliminating candidates based on first bytes:
Let’s go, I will use “Duplicate Find Finder” on Windows XP, it is super.
@Menard,
Just use package manager to install fslint as shown.
Same thing with Fedora Linux, No such package called “fslint“.
@Sentile,
I have already added a note about fsline tool, please read:
"http://archive.ubuntu.com/ubuntu/pool/universe/f/fslint/fslint_2.46-1_all.deb"is not a command!You need to download it with wget or similar, and then use “dpkg” to install it!
DuplicateFilesDeleter is one of the best to remove Duplicated files. You can try out DuplicateFilesDeleter : )
I found the answer for installing fslint on Linux Mint 20: Worked for me!
It is not presented in 20.04 LTS repositories because Python 2 deprecated stuff, but you can install it manually:
@Dave,
Thanks for the tip, I will update the article with these instructions for Linux Mint 20.
Worked fine for me!
Sorry but,
Reading package lists… Done
Building dependency tree
Reading state information… Done
Package fslint is not available, but is referred to by another package.
This may mean that the package is missing, has been obsoleted, or
is only available from another source
E: Package ‘fslint’ has no installation candidate
I can’t install dupeguru either (on Linux Mint 20).
Here’s what I got:
@Dave,
Let me check and update the article with the latest instructions for Linux Mint 20…
I got the same thing,…
“sudo add-apt-repository ppa:dupeguru/ppa
Cannot add PPA: ”This PPA does not support focal’ ”
… just saying.
Also dupeGuru is not in the Jammy repos but can be had at https://launchpad.net/~dupeguru/+archive/ubuntu/ppa/+packages
That’s because of you’re using the latest “focal” ubuntu release. “Dupeguru” has packages for “Bionic” and “Xenial” so you can just open ppa source:
and replace “focal” with “bionic“:
then save file run:
I face the problem but I used to delete duplicate tools. thanks for a good article to solve this problem.
Hi! I have many duplicates, but I would like to keep the keywords of all of them when merging them into one book. My hard drive is full of Duplicate File. Is there a way so that I don’t have to copy it by hand? Many people recommenced Duplicate File Deleter. Thanks!
I’m not sure exactly what you’re asking. Can you be more specific?
Interesting tools, but I have read somewhere that using “ls” command with the appropriate options is a simple way to find duplicate files. am I wrong?
“ls” can show you file sizes, but two files being the same size is not the same as them being duplicates.
Also, consider how you would use ls for this in a directory tree with thousands of directories and millions of files.
Ideally, a tool will generate a list of files, optionally excluding eg. those with 0 sizes. Then it will weed out files with unique sizes since we know they don’t have dups. The rest will need checksums computed and compared; a really sophisticated utility might only fingerprint the first MB or so of each file, and the only checksum the whole files if the initial fingerprints aren’t unique. Ie., if I have 10GB files, each of which has a unique first MB, why read through the whole files?
I came here looking for something to find duplicate files on my Synology; pulling files over a GE network to checksum them would take *forever*. To my delight the rdfind binary works just fine as-is.
whilst the article is useful, the advice to backup first is somewhat stupid, you are tying to remove dupes, not create more!
Robert
For accidental removal of needed files/paths during the dedupe process…
Are you kidding? ALWAYS make a backup of anything when you are using unknown tools. It’s just your files. :P
dupeguru is a good tool in this space too. Just saying.
@ThumbOne,
Thanks for notifying about DupeGuru, added in the article.
Using rdfind helped me solve an issue with the number of inodes I had left on my drive. Running the command using the `-makehardlinks` option reduced my inode usage by 70% and my data usage by 23gb!
Thanks for the useful tutorial!
The thing with rdfind is that it’s not working recursively.
Sure it does.
sh-4.3# find . -type d |wc 47 47 1226