The point of logging is to keep your servers happy, healthy, and secure. If you can’t find the data, you can’t use it effectively or efficiently. If you’re not logging what you need, you will miss some critical signs. Meanwhile, if you’re logging too much, you will miss them again because they’ll be buried in so much noise.
Everyone can use an extra pair of eyes to manage Linux logs, whether you’re a beginner, expert, or somewhere in between.
Identify Why the Machine Exists
This might seem like one of those obvious, collective head nod items, but asking “Why?” never really hurt. Before an assistant admin does anything else, they need to know the device’s primary role in the system and why it exists. Then, they can work towards what they need to know about the computer or device itself.
When you know why the machine exists, you can route the call to the right person on your team. Maybe it’s an issue with the application, or maybe it’s a network issue. Once you identify why the machine you’re investigating exists, you can find the right person more quickly.
Collect All the Data In One Place
Not everyone is a Linux expert, and not everyone can name the log file name for everything that’s going on and where it is, and what should be in the log itself.
For example, you might have any (or all!) of the following spitting out Linux logs:
- Web servers
- DNS server
- Firewalls
- Proxy servers
Not every one of these will live on Linux, but 99% do. You can find server logs in the /var/log directory and subdirectory. If your distribution uses Systemd, you need to look in the /var/log/journal. Sometimes applications keep their logs in odd places, which makes finding them tricky.
If you’re collecting all the logs in a single location and normalizing the data, you can look at all the events simultaneously.
Identify the Machine’s Status
You need to know whether the outage is intended or not. In some cases, the outage might be for regular maintenance, and someone ran the shutdown or reboot commands.
In other cases, it could be that the machine crashed.
While the logs spit out a lot of information, they don’t make it easy to find what you’re looking for. Reviewing Linux logs in plain text files written by a Syslog daemon is hard. When reviewing this information on your own, it’s easy to miss the needle of important information hidden in the haystack of plain text.
It’s also extremely time-consuming, especially when you’re trying to figure out what happened to a machine that led to a service outage.
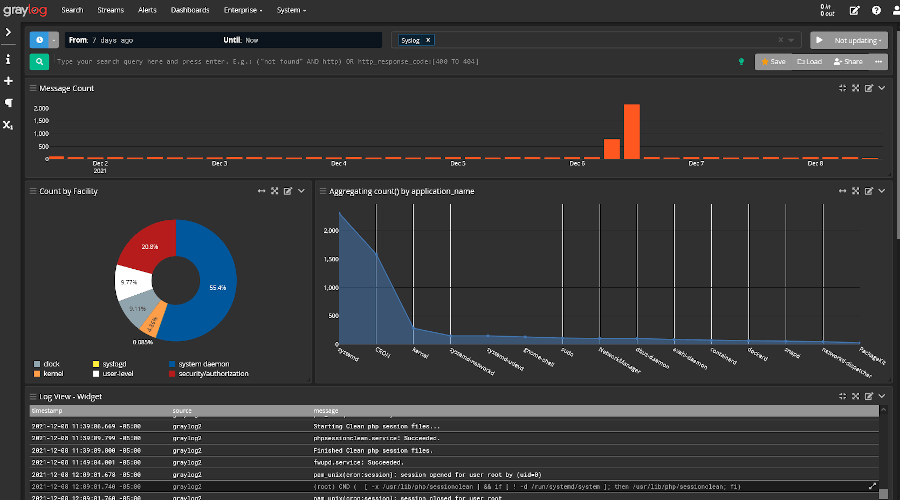
In a centralized log management solution like Graylog, you don’t need to worry about knowing all the log file names or scanning through endless lines of plain text. You can set up dashboards that give you quick visibility.
Download Graylog Open.
Trace Who Did What – And Whether They Should Have
Finally, you need to wrap permissions around everything you do with your Linux logs. This creates the same problem as the status. Everything is in plain text. While you’ve got the information, you will end up with a long list of account activities that you need to scroll through.
To get the information for an individual user’s activities, you need to run multiple searches, especially if you’re not sure who did what and when they did it. This means printing summaries of commands by individual users (one at a time) and searching for the most recent commands that each user executed.
If you’re using a centralized log management solution, like Graylog, you don’t have to run individual searches for each person. In Graylog, you can search for the particular user within the logs, review all their activities, and see visualizations showing you all the interactions.
Getting the Extra Set of Hands You Need
As more places use cloud-native technologies, Linux is becoming more common. However, not everyone has deep expertise with Linux, and that’s ok. The key is finding a way to get the extra set of hands you need so that your team can review the information they need when they need it – in a way that helps them.
When using a centralized log management tool, you get greater visibility, no matter your experience level. You can find the root cause of the issue faster because you get the context you need about how all your machines in the system are connected.
With an easy-to-use interface, more experienced team members can focus on challenging tasks. Instead of doing everything themselves, they can hand off simple tasks to junior members.