In this guide, we will explore two important tools, stress and stress-ng, for conducting comprehensive stress tests on your Linux systems.
As a System Administrator, examining and monitoring how your Linux systems perform under heavy workloads is crucial for maintaining optimal performance and reliability.
Stress testing provides System Administrators and Programmers with valuable insights to:
- Fine-tune system activities and optimize configurations.
- Monitor operating system kernel interfaces under load.
- Test Linux hardware components such as CPU, memory, disk devices, and more to observe their performance under stress.
- Measure different power-consuming loads and their impact on the system.
Linux Stress Testing Tools: stress and stress-ng
stress and stress-ng are essential tools for assessing and testing the performance of Linux systems under various conditions.
stress Tool
stress is a simple yet powerful tool designed to impose a configurable amount of CPU, memory, I/O, or disk stress on a Linux system and, by simulating heavy workloads, allows administrators to observe how the system responds under pressure.
This tool is valuable for identifying potential weaknesses and ensuring that the system can handle demanding tasks without compromising performance.
stress-ng Tool
stress-ng, an extended version of stress, goes beyond the basic functionalities of its predecessor.
It provides a wider range of stress tests, covering not only CPU, memory, I/O, and disk stress but also incorporating additional tests for things like inter-process communication, sockets, and various file operations.
Both stress and stress-ng contribute significantly to the proactive management of Linux systems, enabling administrators and programmers to optimize system configurations, identify potential issues, and enhance overall system reliability.
How to Install ‘stress’ Tool in Linux
To install stress on Linux, use the following appropriate command for your specific Linux distribution.
sudo apt install stress [On Debian, Ubuntu and Mint] sudo yum install stress [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] sudo emerge -a sys-apps/stress [On Gentoo Linux] sudo apk add stress [On Alpine Linux] sudo pacman -S stress [On Arch Linux] sudo zypper install stress [On OpenSUSE] sudo pkg install stress [On FreeBSD]
The general syntax for using stress is:
sudo stress option argument
Here are some key options you can use with stress:
- To spawn
Nworkers spinning onsqrt()function, use the--cpu Noption. - To spawn
Nworkers spinning onsync()function, use the--io Noption. - To spawn
Nworkers spinning onmalloc()/free()functions, use the--vm Noption. - To allocate memory per vm worker, use the
--vm-bytes Noption. - Instead of freeing and reallocating memory resources, you can redirty memory by using the
--vm-keepoption. - Set sleep to
Nseconds before freeing memory by using the--vm-hang Noption. - To
spawn Nworkers spinning onwrite()/unlink()functions, use the--hdd Noption. - You can set a timeout after
Nseconds by using the--timeout Noption. - Set a wait factor of
Nmicroseconds before any work starts by using the--backoff Noption. - To show more detailed information when running stress, use the
-voption. - Use
--helpto view help for using stress or view the manpage.
How to Use stress on Linux Systems
Here are a few example commands to get started with stress:
1. Basic CPU Stress Test
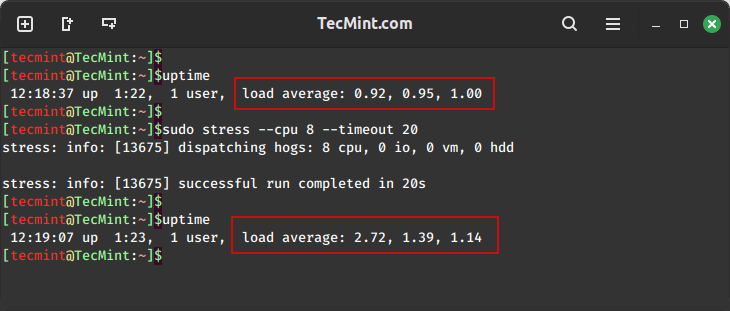
To examine the effect of stress testing, first run the uptime command to note the load average.
Next, run the stress command to spawn 8 workers spinning on sqrt() with a timeout of 20 seconds. After running stress, check the uptime again and compare the load average.
uptime sudo stress --cpu 8 --timeout 20 uptime
2. CPU Stress Test with Verbose Output
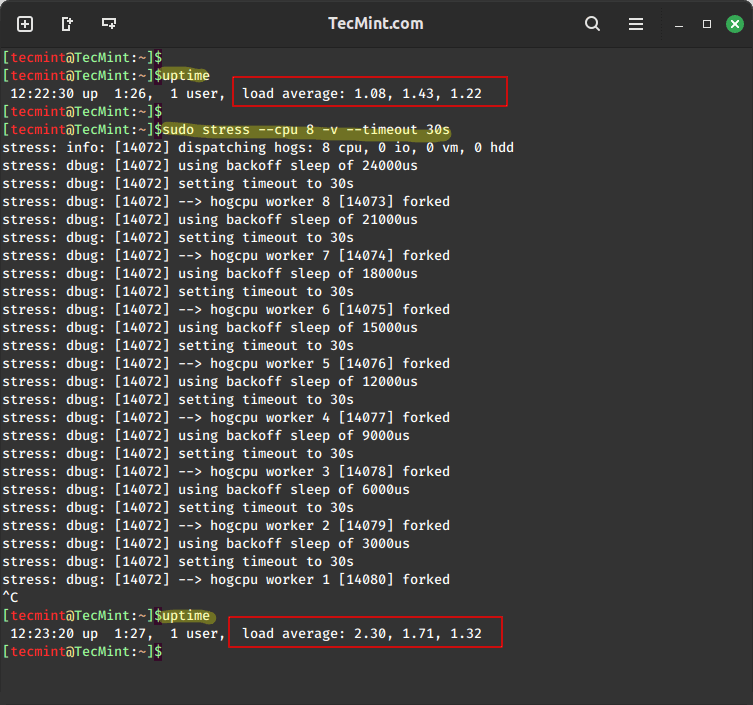
To spawn 8 workers spinning on sqrt() with a timeout of 30 seconds, showing detailed information about the operation, run this command:
uptime sudo stress --cpu 8 -v --timeout 30s uptime
3. Virtual Memory Stress Test
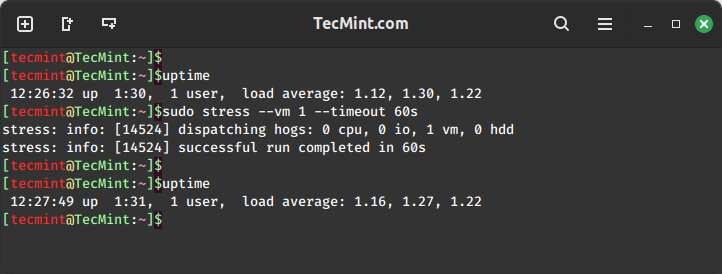
To spawn one worker of malloc() and free() functions with a timeout of 60 seconds, run the following command.
uptime sudo stress --vm 1 --timeout 60s uptime
4. Combined Stress Test (CPU, I/O, and Memory)
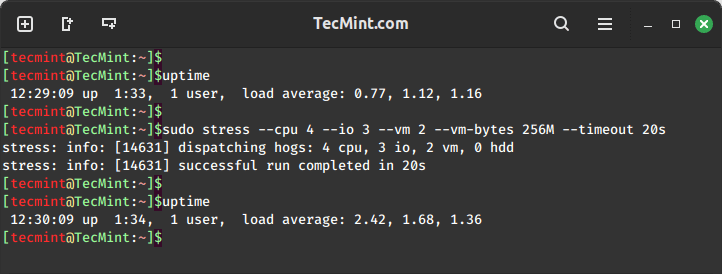
To spawn 4 workers spinning on sqrt(), 2 workers spwaning on sync(), 2 workers on malloc()/free(), with a time out of 20 seconds and allocate a memory of 256MB per vm worker, run this command below.
uptime sudo stress --cpu 4 --io 3 --vm 2 --vm-bytes 256M --timeout 20s uptime
How to Install ‘stress-ng’ Tool in Linux
To install stress-ng on Linux, use the following appropriate command for your specific Linux distribution.
sudo apt install stress-ng [On Debian, Ubuntu and Mint] sudo yum install stress-ng [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] sudo emerge -a sys-apps/stress-ng [On Gentoo Linux] sudo apk add stress-ng [On Alpine Linux] sudo pacman -S stress-ng [On Arch Linux] sudo zypper install stress-ng [On OpenSUSE] sudo pkg install stress-ng [On FreeBSD]
The general syntax for using stress-ng is:
sudo stress-ng option argument
Some of the options that you can use with stress-ng:
- To start
Ninstances of each stress test, use the--all Noption as follows. - To start
Nprocesses to exercise the CPU by sequentially working through all the different CPU stress testing methods, use the--cpu Noption as follows. - To use a given CPU stress testing method, use the
--cpu-methodoption. There are many methods available that you can use, to view the manpage to see all the methods to use. - To stop the CPU stress process after
Nbogo operations, use the--cpu-ops Noption. - To start
N I/Ostress testing processes, use the--io Noption. - To stop io stress processes after
Nbogo operations, use the--io-ops Noption. - To start
Nvm stress testing processes, use the--vm Noption. - To specify the amount of memory per vm process, use the
--vm-bytes Noption. - To stop vm stress processes after
Nbogo operations, use--vm-ops Noptions - Use the
--hdd Noption to startNharddisk exercising processes. - To stop hdd stress processes after
Nbogo operations, use the--hdd-ops Noption. - You can set a timeout after
Nseconds by using the--timeout Noption. - To generate a summary report after bogo operations, you can use
--metricsor--metrics-briefoptions. The--metrics-briefdisplays non-zero metrics. - You can also start
Nprocesses that will create and remove directories using mkdir and rmdir by using the--dir Noption. - To stop directory operations processes use
--dir-ops Noptions. - To start
N CPUconsuming processes that will exercise the present nice levels, include the--nice Noption. When using this option, every iteration will fork off a child process that runs through all the different nice levels running a busy loop for 0.1 seconds per level, and then exits. - To stop nice loops, use the
--nice-ops Noption as follows. - To start
Nprocesses that change the file mode bits via chmod(2) and fchmod(2) on the same file, use the--chmod Noption. Remember the greater the value for N then the more contention on the file. The stressor will work through all the combinations of mode bits that you specify with chmod(2). - You can stop chmod operations by the
--chmod-ops Noption. - You can use the
-voption to display more information about ongoing operations. - Use
-hto view help forstress-ng.
How to Use ‘stress-ng’ on Linux Systems
The following are a few stress-ng test example commands to get started:
1. CPU Stress Test with Metrics
To run 8 CPU stressors with a timeout of 60 seconds and a summary at the end of operations.
uptime sudo stress-ng --cpu 8 --timeout 60 --metrics-brief uptime
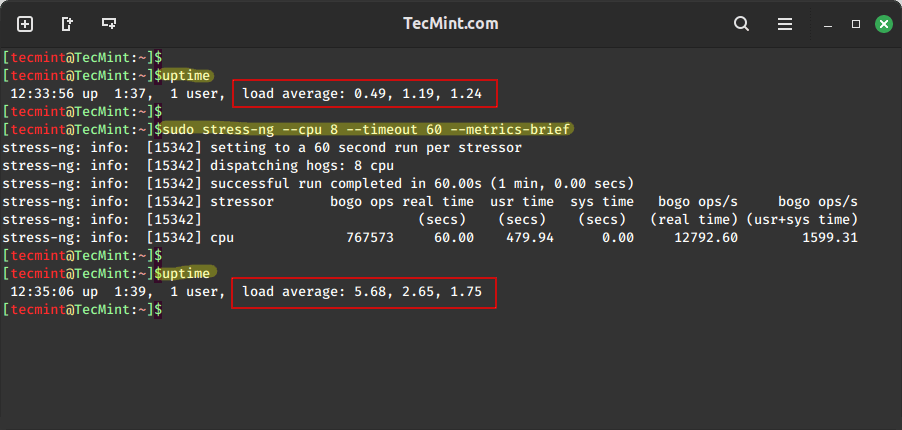
2. Specific CPU Method Test (FFT)
To run 4 FFT CPU stressors with a timeout of 2 minutes.
uptime sudo stress-ng --cpu 4 --cpu-method fft --timeout 2m uptime
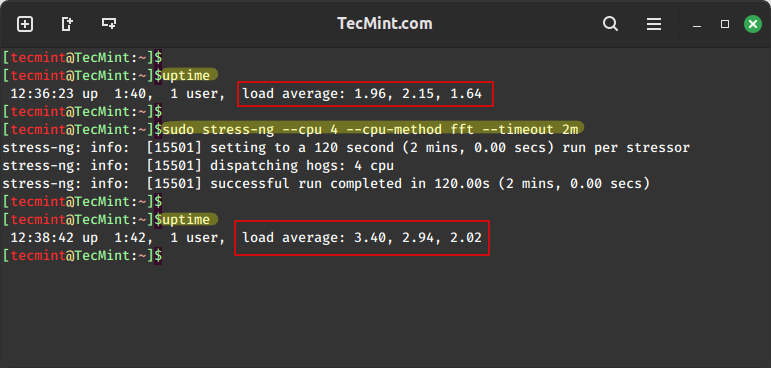
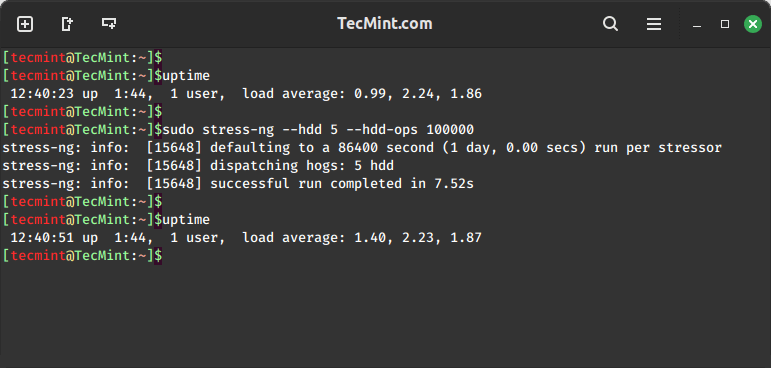
3. Hard Drive Stress Test
To run 5 hdd stressors and stop after 100000 bogo operations, run this command.
uptime sudo stress-ng --hdd 5 --hdd-ops 100000 uptime
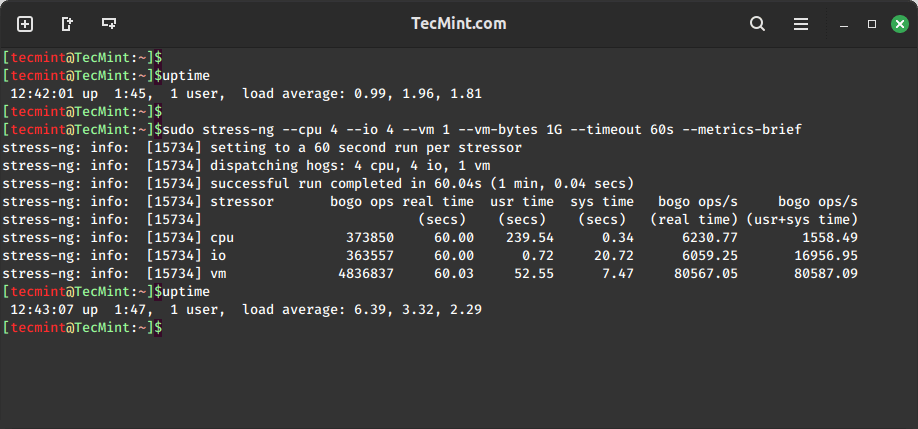
4. Combined Stress Test (CPU, I/O, and Virtual Memory)
To run 8 CPU stressors, 4 I/O stressors, and 1 virtual memory stressor using 1GB of virtual memory for one minute, run this command below.
uptime sudo stress-ng --cpu 4 --io 4 --vm 1 --vm-bytes 1G --timeout 60s --metrics-brief uptime
Real-World Use Cases for Stress Testing in Linux
Understanding when and why to use stress testing tools can help you maintain better system health.
1. Load Testing Before New Server Deployment
Before putting a new server into production, run comprehensive stress tests to ensure it can handle expected workloads, which will help you identify hardware issues early:
sudo stress-ng --cpu 0 --vm 2 --vm-bytes 80% --timeout 10m --metrics-brief
The --cpu 0 option automatically uses all available CPU cores, while --vm-bytes 80% uses 80% of available memory.
2. Testing Load After Hardware Upgrades
After upgrading RAM, CPU, or storage, verify that the new hardware is functioning correctly:
sudo stress-ng --cpu 0 --io 4 --hdd 2 --timeout 5m --verify
The --verify option checks that the stress test operations are producing correct results.
3. Reproducing Production Load
Simulate production workload patterns to test system stability before deploying new applications:
sudo stress-ng --cpu 4 --cpu-load 75 --vm 2 --vm-bytes 2G --timeout 30m
The --cpu-load 75 option keeps CPU usage at approximately 75% rather than maxing it out.
Summary
As recommended, these tools should be used with superuser privileges due to their significant impact on system resources.
Both stress and stress-ng are excellent tools for general System Administration tasks in Linux environments.
Understanding how your systems perform under stress helps you make informed decisions about capacity planning, hardware upgrades, and system optimization.
I hope this guide was useful. If you have any additional ideas on how to test the health status of your system using these tools or any other stress testing utilities, feel free to share your thoughts in the comments below.




Great stuff, but I’m wondering how can I put this stress test on my ESXi host without creating any new VM.
When I try to GPU burn test there are errors showing the:
gpu_burn-drv.cpp:in function int main(int, char**)
gpu_burn-drv.cpp:816:23: error: runtime_error is not a member of std throw std: : runtime_error("No cuda capable gpu found.\n)
But when I install ubuntu on the same server GPU burn test is ok so I can’t understand what is the issue so anyone tells me what to do……
I am using this stress-ng image and applying chaos at K8’s level as I am building chaos as a service. I am planning to put CPU stress. I was expecting the CPU % to spike > 80%. My hypothesis is similar to your uptime values ~ 1- 2% and when I apply CPU stress it is hardly spiking up to 10%. I tried various params but this is the max spike I get. Can we ever make CPU stress > 80% ? as I see even your load averages pretty low.
--vm-bytesis NOT per vm worker but for all workers combined, so you can put almost all your memory if you boot without X.@Florian
Many thanks for the correction, we will cross check this.
Do we have this tool in freeBSD?
@Shashi,
Yes, you can install stress-ng tool on FreeBSD system to imposes certain types of high CPU Load on your FreeBSD based Unix system.
This stress-ng tool can be installed via ports as shown.
Just a tiny annoyance…
It’s “Spawn”, not “Spwan”
@JLockard,
Thanks for notifying about that typo, corrected in the writeup..
The article states: “It is highly recommended that you use these tools with root user privileges”. The manual does not recommend this:
Running stress-ng with root privileges will adjust out of memory set‐
tings on Linux systems to make the stressors unkillable in low memory
situations, so use this judiciously. With the appropriate privilege,
stress-ng can allow the ionice class and ionice levels to be adjusted,
again, this should be used with care.