As Linux users, we interact with various types of files on a regular basis. One of the most common file types on any computer system is a plain text file. Oftentimes, it is a very common requirement to find the required text in these files.
However, this simple task quickly becomes annoying if the file contains duplicate entries. In such cases, we can use the uniq command to filter duplicate text efficiently.
In Linux, we can use the uniq command that comes in handy when we want to list or remove duplicate lines that present adjacently.
Apart from this, we can also use the uniq command to count duplicate entries. It is important to note that, the uniq command works only when duplicate entries are adjacent.
In this simple guide, we will discuss the uniq command in-depth with practical examples in Linux.
uniq Command Syntax
The syntax of the uniq command is very easy to understand and is similar to other Linux commands:
$ uniq [OPTIONS] [INPUT] [OUTPUT]
It is important to note that, all the options and parameters of the uniq command are optional.
Creating Sample Text File
To begin, first, let’s create a simple text file with a vi editor and add the following duplicate contents located in the adjacent lines.
$ vi linux-distributions.txt $ cat linux-distributions.txt
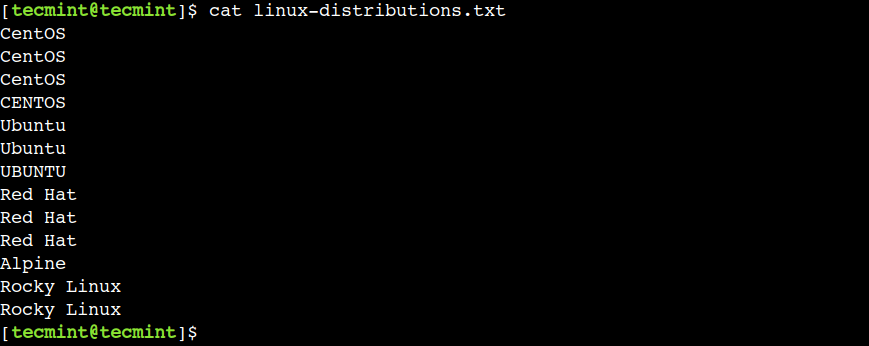
Now, let’s use this file to understand the usage of the uniq command.
1. Remove Duplicate Lines from a Text File
One of the common uses of the uniq command is to remove the adjacent duplicate lines from the text file as shown.
$ uniq linux-distributions.txt
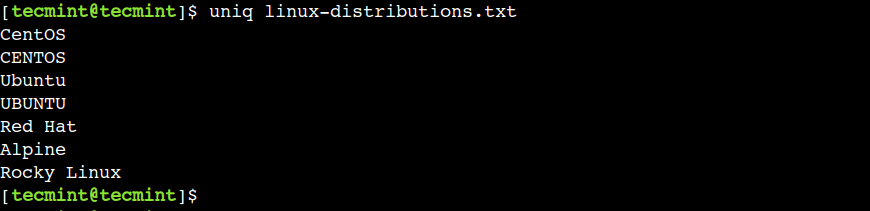
In the above output, we can see that the uniq command has successfully eliminated the duplicated lines.
2. Count Duplicated Lines in a Text File
In the previous example, we saw how to remove duplicate lines. However, sometimes we also want to know how many times the duplicate line appears.
We can achieve this using the -c option as shown in the below example:
$ uniq -c linux-distributions.txt
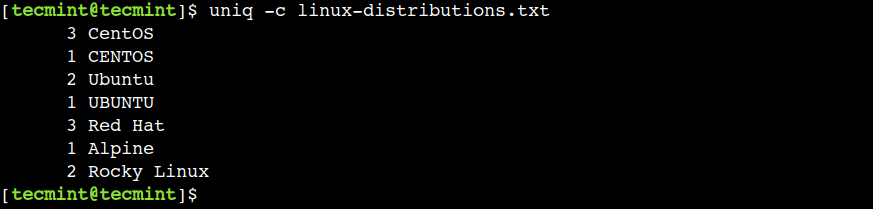
In the above output, the first column represents the number of times the line is repeated.
3. Remove Duplicates with Case Insensitive
By default, the uniq command works in a case-sensitive way. However, we can disable this default behavior by using the -i option as shown.
$ uniq -i linux-distributions.txt

In this example, we can observe that now, the string Ubuntu and UBUNTU is treated as same. Along with this, the same happens with the string CentOS and CENTOS.
4. Print Only Duplicate Lines from a File
Sometimes, we want just want to print the duplicate lines from a text file, in that case, you can use the -d option as shown.
$ uniq -d linux-distributions.txt

In the above output, we can see that the uniq command shows the duplicate entry from each group.
5. Print All Duplicate Lines from a File
In the previous example, we saw how to display a duplicate line from each group. In a similar way, we can also show all the duplicates lines using the -D option:
$ uniq -D linux-distributions.txt
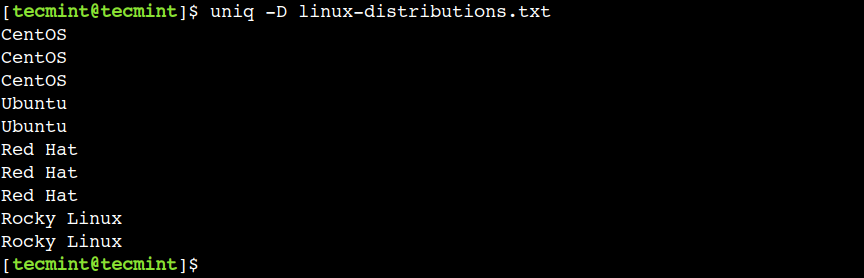
The above output doesn’t show the text UBUNTU, CENTOS, and Alpine as those are uniq lines.
6. Show Duplicate Lines By Groups in a New Line
In the previous example, we printed all duplicate lines. However, we can make the same output more readable by separating each group by a new line.
Let’s use the --all-repeated=separate option to achieve the same:
$ uniq --all-repeated=separate linux-distributions.txt
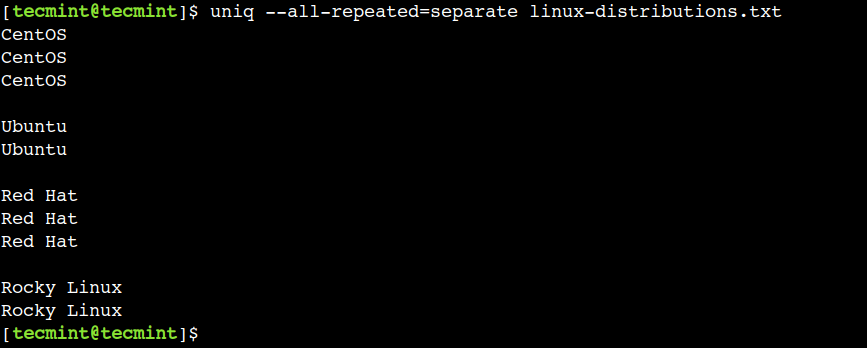
In the above output, we can see that each repeated group is separated by a new line delimiter.
7. Print Only Unique Lines from a File
In previous examples, we saw how to print duplicate lines. Similarly, we can also instruct the uniq command to print non-duplicate lines only.
Now, let’s use the -u option to print unique lines only:
$ uniq -u linux-distributions.txt

Here, we can see that the uniq command displays the lines that aren’t duplicated.
8. Remove Non-adjacent Duplicate Lines in File
One of the trivial limitations of the uniq command is that it only removes adjacent duplicate entries. However, sometimes we want to remove the duplicate entries regardless of their order in the given file.
In such cases, first, we can sort the file contents and then pipe that output to the uniq command as shown.
$ sort linux-distributions.txt | uniq
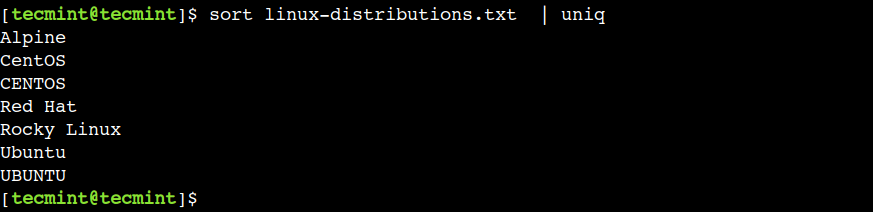
In this example, we used the sort and uniq commands without any options. However, we can also combine other supported options with these commands.
Conclusion
In this guide, we learned the uniq command using practical examples. Do you know of any other best example of the uniq command in Linux? Let us know your views in the comments below.




Dear Sir,
I don’t have very good knowledge as you but I like your all technical-related posts. If any more beautiful Linux tricks you have please post me in my email in the form of a pdf file.