We are living in a world where data is growing in an unpredictable way and it our need to store this data, whether it is structured or unstructured, in an efficient manner. Distributed computing systems offer a wide array of advantages over centralized computing systems. Here data is stored in a distributed way with several nodes as servers.

The concept of a metadata server is no longer needed in a distributed file system. In distributed file systems, it offers a common view point of all the files separated among different servers. Files/directories on these storage servers are accessed in normal ways.
For example, the permissions for files/directories can be set as in usual system permission model, i.e. the owner, group and others. The access to the file system basically depends on how the particular protocol is designed to work on the same.
What is GlusterFS?
GlusterFS is a distributed file system defined to be used in user space, i.e. File System in User Space (FUSE). It is a software based file system which accounts to its own flexibility feature.
Look at the following figure which schematically represents the position of GlusterFS in a hierarchical model. By default TCP protocol will be used by GlusterFS.
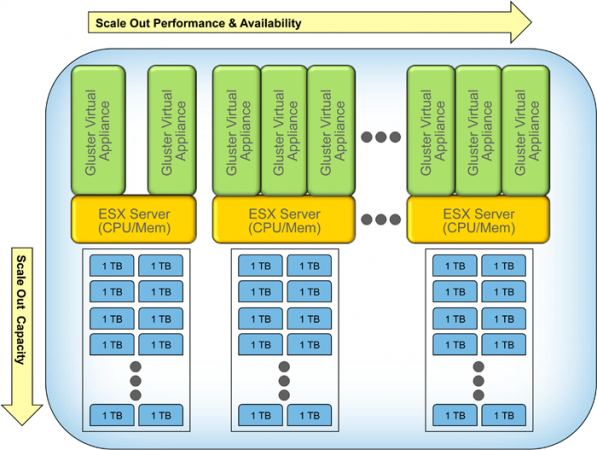
Advantages to GlusterFS
- Innovation – It eliminates the metadata and can dramtically improve the performance which will help us to unify data and objects.
- Elasticity – Adapted to growth and reduction of size of the data.
- Scale Linearly – It has availability to petabytes and beyond.
- Simplicity – It is easy to manage and independent from kernel while running in user space.
What makes Gluster outstanding among other distributed file systems?
- Salable – Absence of a metadata server provides a faster file system.
- Affordable – It deploys on commodity hardware.
- Flexible – As I said earlier, GlusterFS is a software only file system. Here data is stored on native file systems like ext4, xfs etc.
- Open Source – Currently GlusterFS is maintained by Red Hat Inc, a billion dollar open source company, as part of Red Hat Storage.
Storage concepts in GlusterFS
- Brick – Brick is basically any directory that is meant to be shared among the trusted storage pool.
- Trusted Storage Pool – is a collection of these shared files/directories, which are based on the designed protocol.
- Block Storage – They are devices through which the data is being moved across systems in the form of blocks.
- Cluster – In Red Hat Storage, both cluster and trusted storage pool convey the same meaning of collaboration of storage servers based on a defined protocol.
- Distributed File System – A file system in which data is spread over different nodes where users can access the file without knowing the actual location of the file. User doesn’t experience the feel of remote access.
- FUSE – It is a loadable kernel module which allows users to create file systems above kernel without involving any of the kernel code.
- glusterd – glusterd is the GlusterFS management daemon which is the backbone of file system which will be running throughout the whole time whenever the servers are in active state.
- POSIX – Portable Operating System Interface (POSIX) is the family of standards defined by the IEEE as a solution to the compatibility between Unix-variants in the form of an Application Programmable Interface (API).
- RAID – Redundant Array of Independent Disks (RAID) is a technology that gives increased storage reliability through redundancy.
- Subvolume – A brick after being processed by least at one translator.
- Translator – A translator is that piece of code which performs the basic actions initiated by the user from the mount point. It connects one or more sub volumes.
- Volume – A volumes is a logical collection of bricks. All the operations are based on the different types of volumes created by the user.
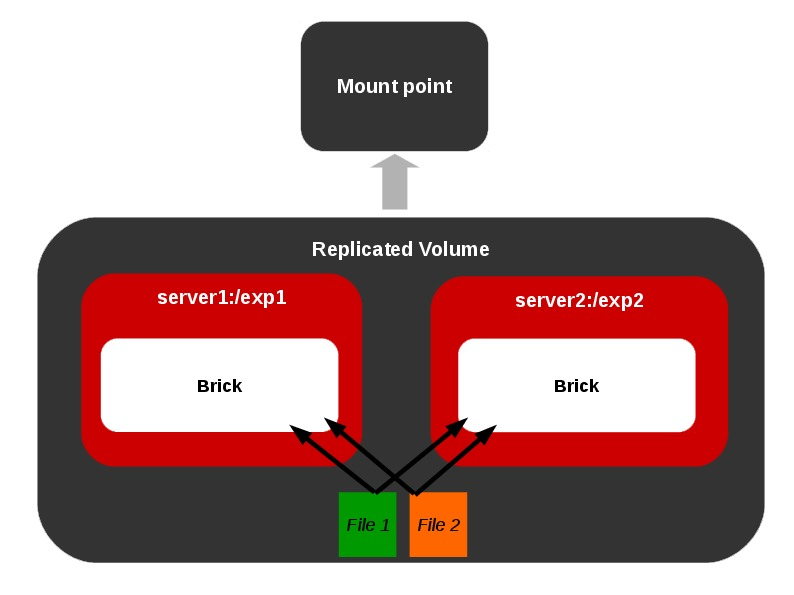
Different Types of Volumes
Representations of different types of volumes and combinations among these basic volume types are also allowed as shown below.
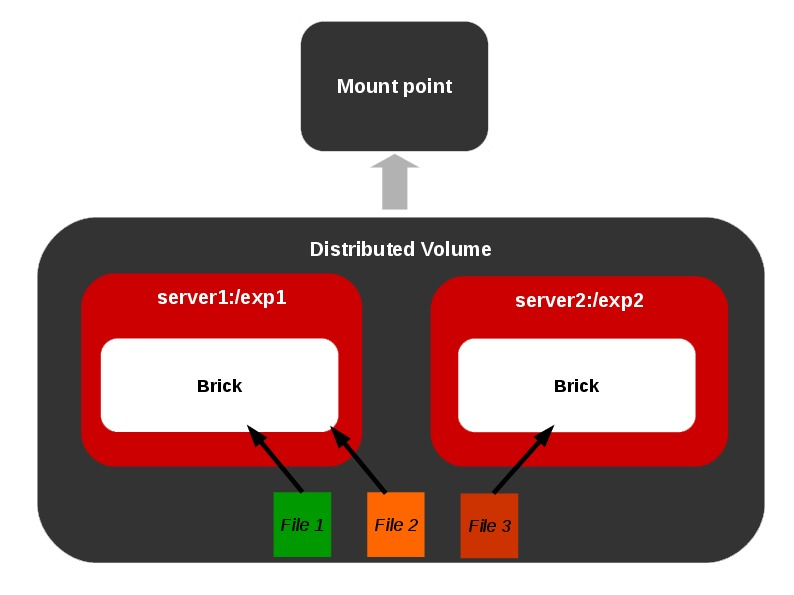
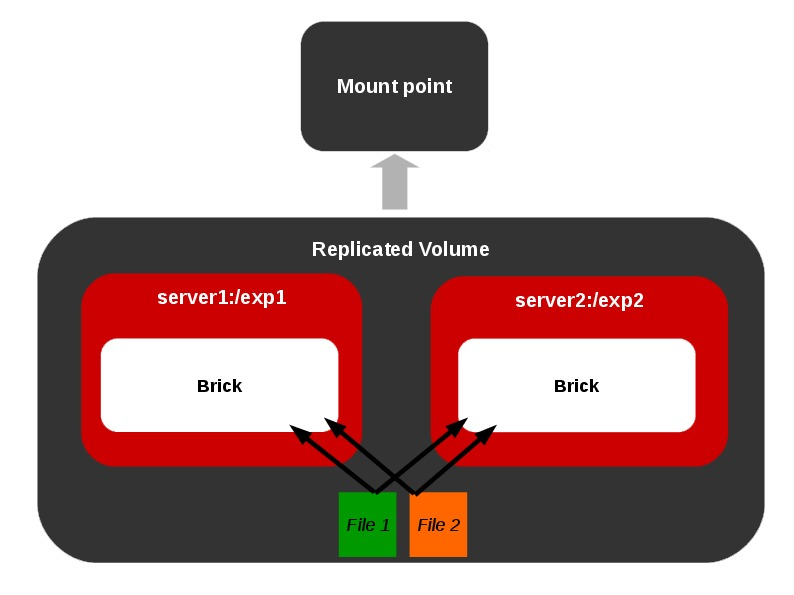
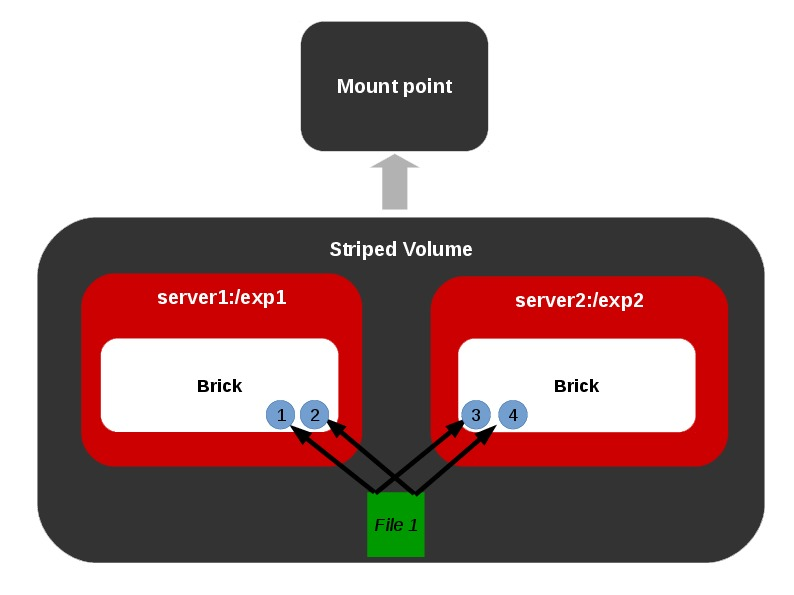
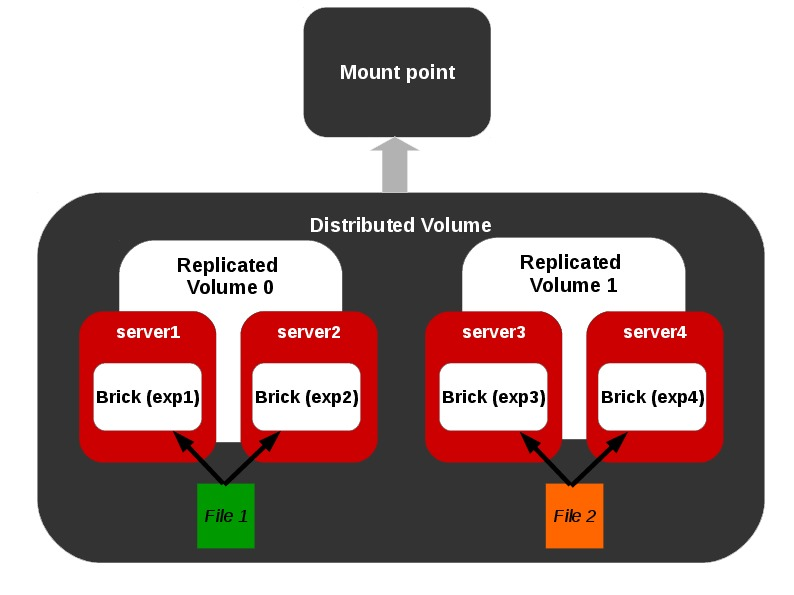
Distributed Replicated Volume
Representation of a distributed-replicated volume.
Installation of GlusterFS in RHEL/CentOS and Fedora
In this article, we will be installing and configuring GlusterFS for the first time for high availability of storage. For this, we’re taking two servers to create volumes and replicate data between them.
Step :1 Have at least two nodes
- Install CentOS 6.5 (or any other OS) on two nodes.
- Set hostnames named “server1” and “server2“.
- A working network connection.
- Storage disk on both nodes named “/data/brick“.
Step 2: Enable EPEL and GlusterFS Repository
Before Installing GlusterFS on both the servers, we need to enable EPEL and GlusterFS repositories in order to satisfy external dependencies. Use the following link to install and enable epel repository under both the systems.
Next, we need to enable GlusterFs repository on both servers.
# wget -P /etc/yum.repos.d http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/glusterfs-epel.repo
Step 3: Installing GlusterFS
Install the software on both servers.
# yum install glusterfs-server
Start the GlusterFS management daemon.
# service glusterd start
Now check the status of daemon.
# service glusterd status
Sample Output
service glusterd start service glusterd status glusterd.service - LSB: glusterfs server Loaded: loaded (/etc/rc.d/init.d/glusterd) Active: active (running) since Mon, 13 Aug 2012 13:02:11 -0700; 2s ago Process: 19254 ExecStart=/etc/rc.d/init.d/glusterd start (code=exited, status=0/SUCCESS) CGroup: name=systemd:/system/glusterd.service ├ 19260 /usr/sbin/glusterd -p /run/glusterd.pid ├ 19304 /usr/sbin/glusterfsd --xlator-option georep-server.listen-port=24009 -s localhost... └ 19309 /usr/sbin/glusterfs -f /var/lib/glusterd/nfs/nfs-server.vol -p /var/lib/glusterd/...
Step 4: Configure SELinux and iptables
Open ‘/etc/sysconfig/selinux‘ and change SELinux to either “permissive” or “disabled” mode on both the servers. Save and close the file.
# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted
Next, flush the iptables in both nodes or need to allow access to the other node via iptables.
# iptables -F
Step 5: Configure the Trusted Pool
Run the following command on ‘Server1‘.
gluster peer probe server2
Run the following command on ‘Server2‘.
gluster peer probe server1
Note: Once this pool has been connected, only trusted users may probe new servers into this pool.
Step 6: Set up a GlusterFS Volume
On both server1 and server2.
# mkdir /data/brick/gv0
Create a volume On any single server and start the volume. Here, I’ve taken ‘Server1‘.
# gluster volume create gv0 replica 2 server1:/data/brick1/gv0 server2:/data/brick1/gv0 # gluster volume start gv0
Next, confirm the status of volume.
# gluster volume info
Note: If in-case volume is not started, the error messages are logged under ‘/var/log/glusterfs‘ on one or both the servers.
Step 7: Verify GlusterFS Volume
Mount the volume to a directory under ‘/mnt‘.
# mount -t glusterfs server1:/gv0 /mnt
Now you can create, edit files on the mount point as a single view of the file system.
Features of GlusterFS
- Self-heal – If any of the bricks in a replicated volume are down and users modify the files within the other brick, the automatic self-heal daemon will come into action as soon as the brick is up next time and the transactions occurred during the down time are synced accordingly.
- Rebalance – If we add a new brick to an existing volume, where large amount of data was previously residing, we can perform a rebalance operation to distribute the data among all the bricks including the newly added brick.
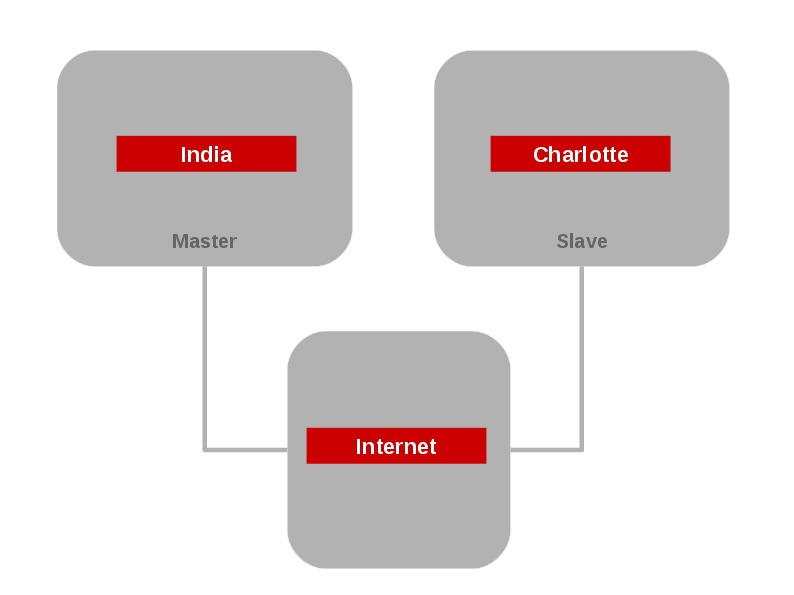
- Geo-replication – It provides back-ups of data for disaster recovery. Here comes the concept of master and slave volumes. So that if master is down whole of the data can be accessed via slave. This feature is used to sync data between geographically separated servers. Initializing a geo-replication session requires a series of gluster commands.
Here, is the following screen grab that shows the Geo-replication module.
Reference Links
That’s it for now!. Stay updated for the detailed description on features like Self-heal and Re-balance, Geo-replication, etc in my upcoming articles.
Thank you for the very informative article.
I have also created a volume and mounted using VM.
Created files from different nodes and could access them.
Few questions:
1- Is GFS suitable for embedded applications?
2- Is the file accessible while it is under replication?
3- Where can we get different characteristics or use cases of GFS?
4- How to check performance and load calculation ?
Hi Kunal,
Glad to hear that you could come up with a working GlusterFS setup. I’ll try to answer your questions as far as I can.
1. I have to admit that I never had any experience with embedded applications. All I can say is that GlusterFS is a clean and simple POSIX-compatible userspace file system. In that regard, I have seen articles describing GlusterFS configured with Raspberry Pi and so on. I hope that helps to look for possible developments in the embedded world.
2. To the best of my knowledge there is no server-side replication happening in GlusterFS. Everything is on the fly as in modifications or updates should happen simultaneously to replica sets.
Therefore it boils down to how effectively file access is maintained using locks or similar mechanisms to avoid data corruption. Because in the best-case scenario you don’t need to worry about any replication happening while files are being accessed by clients.
3. QEMU integration is something I can tell from the top of my mind. I’m sure you will be able to find articles(old) from gluster.org explaining the architecture behind the use case. I’m adding one such link which I could get hold of quickly. Otherwise media backup/archival is also an area where GlusterFS deployments are common. Also, see the second link with references to different use cases.
* https://www.gluster.org/qemu-glusterfs-native-integration/
* https://www.gluster.org/category/use-case/
4. “smallfile” [https://github.com/distributed-system-analysis/smallfile] is a great tool for benchmarking POSIX-like filesystems. For a quick check, you may also look at periodic performance reports (search for keyword ‘report’) sent to the Gluster Devel mailing list covering various workloads like smallfile, large files etc.
Hello, I want to know the way processing store file on storage servers. when i deploy glusterfs with replicated volume, the client will send a file to all storage servers or the client will send a file to one server then the server will send to another.
The whole logic of file distribution and replication resides on the client side stack of GlusterFS. For example, client will perform a write operation to both servers in a replica set of 2 . There is no communication between the servers(or bricks in terms of GlusterFS) themselves.
But with GlusterFS 4.0, overall structure is intended to change which also includes the concept of server-side replication termed as JBR(Journal Based Replication). More details on JBR can be found at Red Hat – Next Generation File Replication system in Gluster FS
Stay tuned to GlusterFS mailing lists for more updates or jump into #gluster on Freenode IRC.
It might be nice to put in big bold letters that these steps are for VOLUME REPLICATION ONLY. The other volume types and setup are not explained fully here at all.
Hi Anoop ,
I have followed the article , it was nice that everything works perfect , I have some question regarding glusterfs as
1. I am using two webserver and two storage server , storage server is configured with glusterfs , both are replicating fine with the configurations , I need to mount common share directory which is “gv0” according to your article , I have installed the gluster client on the webserver ,and mount server1:/gv0 to webserver , after this step , replication suddenly stops , as I have mounted node1 on websever when i am creating any file in the gluster server1 then it is not accessible in webserver as well . so I am stucked with this
2. can you please suggest how gluster allows high availablity , as i am mounting node1 on webserver , if node1 will be down then how glusterfs will manage files ???
Thanks,
Ashish
Thanks for your good words. Answering your questions:
[1] You must always create/modify/delete files inside GlusterFS through mount points. As far as I can understand from your explanation you have attempted to create a file directly on one of your storage server which is a wrong way to do things and can result in failures.
[2] Even if you mount via node1 on your web server, GlusterFS client process will fetch the required configuration files(.vol files) from node1 and establishes connections to both node1 and node2 with the web server from which the mount was done. Thus client can still live with the other server node if one of them is down. Self-healing of files will take place as soon as the offline mode becomes online. You can refer the second part in this series [https://www.tecmint.com/perform-self-heal-and-re-balance-operations-in-gluster-file-system/] to get more insight.
Please let me know if you are not satisfied with the above explanation.
Nice guide i have followed the and created gfs volume replicated
over 2 nodes (2 nos of i3 system with 4gb ram 2 SATA hdd each 1
for os and another for gluster volume) .Replication works fine and created
samba share on that volume but the data transfer rate to that share is
pathetic (max 3mb speed)from windows7 or 8 system .when i mod prob fuse, there is no
error at all.Do i miss anything ? Pl help
I think you are using fuse mount to access gluster volume as Samba share. If yes, you do have an alternative way of accessing gluster volumes from windows clients via our API, aka libgfapi, as described in the following link.
https://lalatendumohanty.wordpress.com/2014/02/11/using-glusterfs-with-samba-and-samba-vfs-plugin-for-glusterfs-on-fedora-20/
I am always ready to help in case of any errors with Samba shares for gluster volumes.
Thank You Anoop for your response .I have followed the guide you have referred with samba-vfs-plugin but getting maximum speed of 11MB . Created vol using strip for performance since we have plans to store and use large files (size of about 1gb) .Is there any thing that i am missing technically.As i mentiond i am using 2 i3 systems with 2 hdd each ,one hdd from each is dedicated to create gfs volume.Can we achieve 100MB or more with GFS,Samba-vfs and this hardware? I read many article which makes me think possible.
Can you check for speed with an XFS partition instead of GlusterFS and share your results? If you see much better performance on XFS, then it’s something to look into more deeply.
I will wait for your reply. Along with the results please provide the following details:
* Operating system
* GlusterFS version
* Samba version
* Output of the following command:
gluster volume info
* GlusterFS volume share section from smb.conf
* Any suspicious warning, error logs from gluster side
* Whether Samba is running independently from Gluster nodes?
thank you so much for the article, it really help me. but I have one problem here, after i reboot my pc i cant mount the server anymore, it works really well before I reboot it.
“/usr/bin/fusermount-glusterfs: mount failed: No such device
Mount failed. Please check the log file for more details.”
I use ip address of the server instead of hostname, do you have any idea? thank you
Some first come thoughts:
[1] Verify the network route to server from the client.
[2] Make sure that the volume is started state. (bricks are up or not).
[3] Check whether GlusterFS management daemon (glusterd) is running on the server while mount command is issued.
[4] If you are using fstab to mount automatically on reboot, please provide me the corresponding entry.
If everything is up and running, would you mind providing the client log in some way (I prefer fpaste) for further investigation and also the glusterfs version you are running on server?
solve it, thanks. I have to add “modprobe –first-time fuse” and restart all containers to make it work everytime I reboot it.
i cannot mount the volume, it said “Mount failed. Please check the log file for more details.” any idea why? thanks
Hi nando,
Please check the following:
[1] Make sure that the required volume is started. {gluster volume status }
[2] Check whether glusterfs daemon(glusterd) is running on the IP you used to mount
[3] Make sure that the mount command is ran correctly. {mount -t glusterfs :/ }
If above things are fine, can you please fpaste the mount log i.e, /var/log/glusterfs/.log and reply here with the link. It would be better if you can provide the output of gluster volume info, gluster volume status and the whole command used to mount the glusterfs volume.
Hi Anoop.. first of all many thanks for such a simple and informative article on glusterfs.
I have one doubt.. If I build glusterfs on 2 nodes (server1 and server2) and mount it on client as server1:/gv0 .
if server1 goes down due to some reason.. we need to again mount it on client as server2:/brick to restore functionality. Am I correct?
Is there a way for client to automatically fix the above issue and mount it as server2:/brick .. I mean failover to server 2 till server1 comes online..
Hi Vaibhav,
Thanks and let me start with explaining the background for your doubt.
The example listed in the article explains the glusterfs native mount (FUSE mount). As soon as you mount the volume on client, it establishes direct connections between glusterfsd processes (which are the brick processes on servers). After mounting, if somehow glusterd (GlusterFS management daemon) got killed on the server which was used during mount, it doesn’t affect the I/O. Hereafter the I/O request/responses are exchanged between glusterfs (mount process) and glusterfsds (brick processes).
Now coming to your question.. What happens if the whole server went down which obviously kills glusterd and possibly glusterfsds (if there are bricks running on that server)? Remember that GlusterFS is a distributed file system. Unless you have configured a replica cluster, data residing on the brick (for which it went down) will not be listed on mount and I/O for files on that brick will fail. Even in that case mount still exists and will show the contents from other bricks (if there exists more than one brick). Here comes the importance of replica cluster.
Suppose you managed to setup a replica cluster over server1 and server2 and client mounts the volume using server1. In this scenario even if server1 goes offline, it will not cause any I/O to fail because the other replica is still alive. As soon as server1 comes back online it automatically performs the healing operations to maintain the consistency of data across the volume.
All the above facts are related to FUSE mounts. The concept of fail-over in GlusterFS has been integrated with NFS exports and Samba shares with the help of pacemaker, corosync and pcs (High Availability Cluster) and it is an ongoing development in Gluster community. There you can configure VIPs (Virtual IPs) in order to handle fail-over cases. You can always reach out to #gluster on freenode or subscribe to gluster-users mailing list for further details on High Availability Resource Management in GlusterFS.
I wish this articale could be more detailed and new-bee oriented. I’m stuck at mkdir /data/brick/gv0 – how do I say to my sdb1 that it it’s now a brick?
I don’t get you clearly. /data/brick/gv0 is just a export directory. In GlusterFS semantics, it is called as a brick. If I understand correctly, you can always mount /dev/sdb1 and used sub-directories under sdb1 as bricks. You need to specify exact path while creating the volume.
Found great post about content distribution testing in GlusteFS – http://sysadm.pp.ua/linux/glusterfs-setup.html Maybe it will be usefull
I just want to make /home partition as gluster volume…
What do I need to do ? Please help… and Thanks in advance..
Thanks , it works great . ISCSI -Target + GlusterFS vs High Availability ?
Sorry for the *very very* late reply. I somehow didn’t receive the notification regarding this comment. I hope by this time, you might have figured out on how to forward on this integration. If not the following doc may be helpful for GlusterFS iSCSI.
http://gluster.readthedocs.org/en/latest/Administrator%20Guide/GlusterFS%20iSCSI/
Regarding the high-availability, can you please elaborate more on what you have in your mind? We have progressed a lot in case of HA with the integration of NFS-Ganesha [and its working :) ]. With more details, I can help you with more information.
I am having a hell of a time connecting the peers. They ping right, IPTables was reset. They detect each other on probe. But when trying to create the gv0 it stubbornly says the other host is not connected.
Can I have the output on running ‘gluster peer status’ ? The output must display state of the remote hosts [ those were previously probed ] as
State: Peer in Cluster (Connected)
If host state is different from the above mentioned state, volume operations will fail. Please make sure that glusterd is running and iptables are flushed on all servers [peers]. What about the SELinux status? Can you please paste the output of sestatus ?
hi ,
i am have a question?
server:
10.10.10.51
10.10.10.52
10.10.10.53
10.10.10.54
client:
10.10.10.55
server configure:
gluster mode replica
eg.
gluster volume create gfs replica 4 transport tcp 10.10.10.51:/data/file1 10.10.10.52:/data/file1 10.10.10.53:/data/file1 10.10.10.54:/data/file1 force
client :
mount -t glusterfs 10.10.10.51:/gfs /mnt/gfs
Now ,i am have a question
if one of four server down; eg 10.10.10.51 down.
client is disconnect ,I am need wait 90seconds, client is autoconnect, clinet is ok
How to configure the server to shorten the time.
@Yan
Sorry for the *very late* reply. The notification regarding your comment was accidentally moved to Spam.
If possible, can you re-create the situation and explain to me how the server went down and client got disconnected? What was the error message displayed on the client side when the server went down?
Can you check the volume status while one of the server is down? The volume status output must display a ‘N’ under the online section corresponding to the server which is down at present.
@Sanjay: Thanks.
http://about.me/anoopcs9
@Justdude
You are right. If the path does not exists, we need to provide the -p option for mkdir command. I will update the article with the necessary corrections including the ambiguity in naming the brick directories.
And for gluster daemon to work after reboot you can also make use of the systemctl command as follows
# systemctl enable glusterd
Thanks for your valuable comment on the article.
You need mkdir -p if you create more than one directory at once as in your example.
Also you created brick directory, but in gluster example lines you used brick1..
And for gluster to work after reboot, you need to add it to startup with chkconfig glusterfsd on and chkconfig glusterd on :)
January 18, 2017: Justdude is correct here on both fronts.
Since Gluster’s concept of Bricks is that you can add more, I would change the creation of the folder on both server1 and server2 to the following:
[server1]# mkdir -p /data/brick1/gv0
and
[server2]# mkdir -p /data/brick1/gv0
Good overview Anoop. What city are you based?
Hi, I am a newbie.I have a question here. What would be better NAS(such as Openfiler or NAS4free) or Glusterfs. I am a little bit confused. Thanks for your nice posting.
@Shamimho,
NAS is generally a term used for computer data storage inside a network and GlusterFS is always a way of doing the thing (as we can implement NAS via Samba or NFS etc).
GlusterFS is a scale-out NAS file system. We can implement a NAS with GlusterFS. It is not bound to hardware-level as shown in the Design section above. It operates at user space (FUSE) which is fully software-driven.
So it seems there is no meaning in comparing GlusterFS and NAS.