In my previous article on ‘Introduction to GlusterFS (File System) and Installation – Part 1‘ was just a brief overview of the file system and its advantages describing some basic commands. It is worth mentioning about the two important features, Self-heal and Re-balance, in this article without which explanation on GlusterFS will be of no use. Let us get familiar with the terms Self-heal and Re-balance.
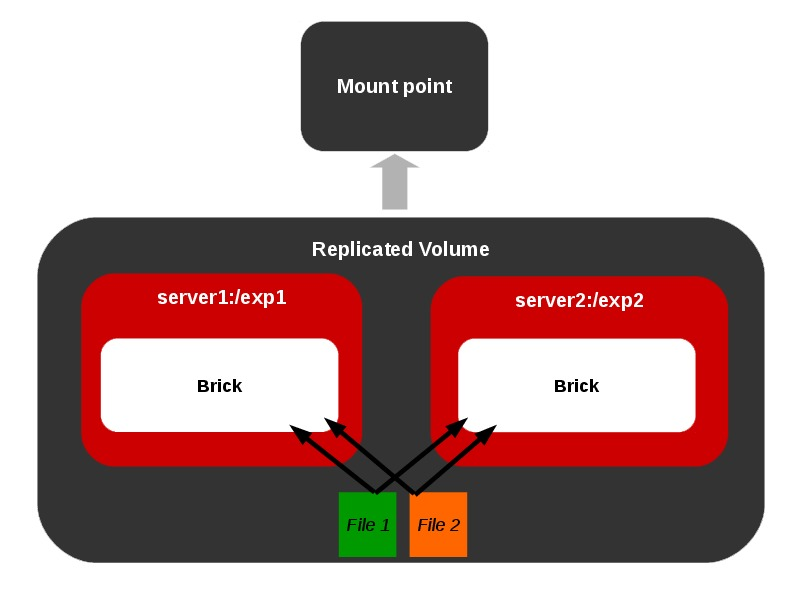
What do we mean by Self-heal on replicated volumes?
This feature is available for replicated volumes. Suppose, we have a replicated volume [minimum replica count 2]. Assume that due to some failures one or more brick among the replica bricks go down for a while and user happen to delete a file from the mount point which will get affected only on the online brick.
When the offline brick comes online at a later time, it is necessary to have that file removed from this brick also i.e. a synchronization between the replica bricks called as healing must be done. Same is the case with creation/modification of files on offline bricks. GlusterFS has an inbuilt self-heal daemon to take care of these situations whenever the bricks become online.
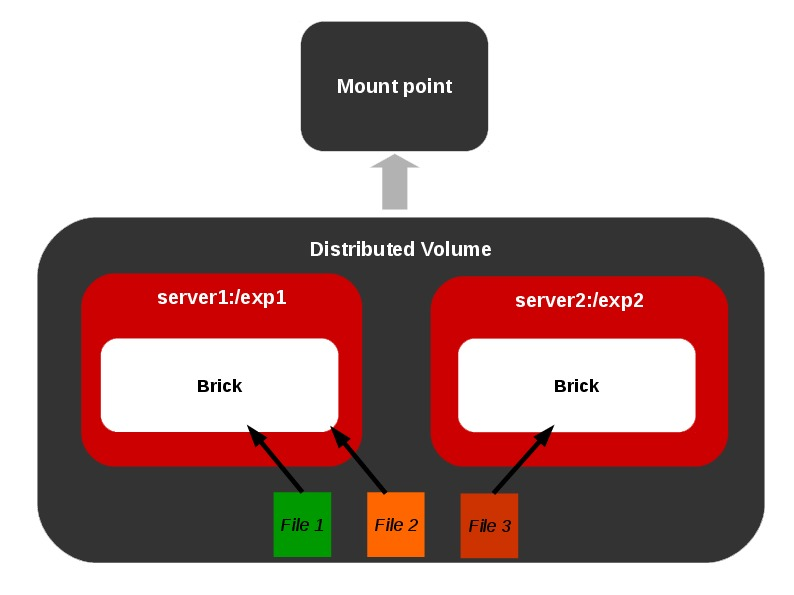
What do we mean by Re-balance?
Consider a distributed volume with only one brick. For instance we create 10 files on the volume through mount point. Now all the files are residing on the same brick since there is only brick in the volume. On adding one more brick to the volume, we may have to re-balance the total number of files among the two bricks. If a volume is expanded or shrunk in GlusterFS, the data needs to be re-balanced among the various bricks included in the volume.
Performing Self-heal in GlusterFS
1. Create a replicated volume using the following command.
$ gluster volume create vol replica 2 192.168.1.16:/home/a 192.168.1.16:/home/b
Note: Creation of a replicated volume with bricks on the same server may raise a warning for which you have to proceed ignoring the same.
2. Start and mount the volume.
$ gluster volume start vol $ mount -t glusterfs 192.168.1.16:/vol /mnt/
3. Create a file from mount point.
$ touch /mnt/foo
4. Verify the same on two replica bricks.
$ ls /home/a/ foo $ ls /home/b/ foo
5. Now send one of the bricks offline by killing the corresponding glusterfs daemon using the PID got from volume status information.
$ gluster volume status vol
Sample Output
Status of volume: vol Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.1.16:/home/a 49152 Y 3799 Brick 192.168.1.16:/home/b 49153 Y 3810 NFS Server on localhost 2049 Y 3824 Self-heal Daemon on localhost N/A Y 3829
Note: See the presence of self-heal daemon on the server.
$ kill 3810
$ gluster volume status vol
Sample Output
Status of volume: vol Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.1.16:/home/a 49152 Y 3799 Brick 192.168.1.16:/home/b N/A N N/A NFS Server on localhost 2049 Y 3824 Self-heal Daemon on localhost N/A Y 3829
Now the second brick is offline.
6. Delete the file foo from mount point and check the contents of the brick.
$ rm -f /mnt/foo $ ls /home/a $ ls /home/b foo
You see foo is still there in second brick.
7. Now bring back the brick online.
$ gluster volume start vol force $ gluster volume status vol
Sample Output
Status of volume: vol Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.1.16:/home/a 49152 Y 3799 Brick 192.168.1.16:/home/b 49153 Y 4110 NFS Server on localhost 2049 Y 4122 Self-heal Daemon on localhost N/A Y 4129
Now the brick is online.
8. Check the contents of bricks.
$ ls /home/a/ $ ls /home/b/
File has been removed from the second brick by the self-heal daemon.
Note: In case of larger files it may take a while for the self-heal operation to be successfully done. You can check the heal status using the following command.
$ gluster volume heal vol info
Performing Re-balance in GlusterFS
1. Create a distributed volume.
$ gluster create volume distribute 192.168.1.16:/home/c
2. Start and mount the volume.
$ gluster volume start distribute $ mount -t glusterfs 192.168.1.16:/distribute /mnt/
3. Create 10 files.
$ touch /mnt/file{1..10}
$ ls /mnt/
file1 file10 file2 file3 file4 file5 file6 file7 file8 file9
$ ls /home/c
file1 file10 file2 file3 file4 file5 file6 file7 file8 file9
4. Add another brick to volume distribute.
$ gluster volume add-brick distribute 192.168.1.16:/home/d $ ls /home/d
5. Do re-balance.
$ gluster volume rebalance distribute start volume rebalance: distribute: success: Starting rebalance on volume distribute has been successful.
6. Check the contents.
$ ls /home/c file1 file2 file5 file6 file8 $ ls /home/d file10 file3 file4 file7 file9
Files has been re-balanced.
Note: You can check the re-balance status by issuing the following command.
$ gluster volume rebalance distribute status
Sample Output
Node Rebalanced-files size scanned failures skipped status run time in secs --------- ----------- --------- -------- --------- ------- -------- ----------------- localhost 5 0Bytes 15 0 0 completed 1.00 volume rebalance: distribute: success:
With this I plan to conclude this series on GlusterFS. Feel free to comment here with your doubts regarding the Self-heal and Re-balance features.

Hii, Thanks a lot.
In section 7, the command “gluster volume start force” is wrong. the correct that is “gluster volume start vol force”
@Behnam,
Thanks, corrected the command in the writeup..
very nice article………!!!!!!!!
Hi,
Nice Article… waiting for more inputs on gluserfs !!!